NO EXECUTE!
(c) 2015 by Darek Mihocka, founder, Emulators.com.
May 8 2015
A look back at my wish list
For the past 8 years in this blog series I have commented on all things related to CPUs, virtual machines, and code optimization. In one of my first posts in 2007 (Part 3) I argued that the Intel x86 instruction set should be redesigned. An instruction set - whether x86, ARM, PowerPC, 6502 - is just a particular encoding. It is a bytecode that contains a sequence of instructions for the hardware CPU to execute. It is a binary interface, an ABI, and as such one can independently modify the two sides of that interface. Every model of AMD or Intel (or Transmeta or Via or Cyrix) x86 CPU is a slightly different implementation and behaves with different timings and performance characteristic; but adhere to the x86 instruction set interface. In Transmeta's case they replaced the hardware implementation of x86 with a simpler VLIW RISC-like processor and used a software decoder, as well as an interpreter and dynamic translator called CMS (Code Morphing Software), to emulate x86. This is similar to what I've done for almost 30 years every time I work on an emulator, from emulating 68040 for a Macintosh emulator to 6502 for an Atari 800 emulator to simulating x86 in C++ for Bochs.
In that post I floated the concept of something I called a "VERT", a Virtual Execution Run Time. Not my original idea, as I said back in that post I was merely connecting the dots and stating something that seemed obvious to me. A VERT would be some sort of binary translation and/or interpretation-based emulator that, much like Transmeta's CMS, runs directly on top of bare hardware and could host arbitrary instruction sets. This would allow you to do one of three things:
- Replace the hardware implementation with a much simpler architecture, what Transmeta did, but extended to support multiple guest instruction sets. Imagine a version of a Linux GRUB loader that happened to be a VERT and could boot arbitrary x86, x64, PowerPC, MIPS, or ARM Linux images on the same system on the same hardware.
- Keep the hardware as-is, but the replace the instruction set that is being emulated. In a later posting (Part 5) I thought out loud about simpler ways to re-encode x86 such that it would be easier to emit, to decode in hardware, or to emulate in software. An instruction set I called VX64 that would have fewer crazy effects than legacy x86 but would have much the same functionality as x86.
- Or, do both, have an ability to interface arbitrary instruction sets to arbitrary hardware implementations by having a robust enough VERT that could be retargeted for various guest and host instruction sets. This is what emulators like QEMU try to be.
So option #1 is basically what Transmeta or Alpha's FX!32 did in the 1990's. Option #2 describes managed runtimes like Java or .NET where a virtual bytecode (Java, MSIL) is emulated on existing hardware. But option #3 is the one that really excited me because it leaves so much wiggle room on both sides of the ISA interface. It would allow the creation of virtual instruction sets that were completely decoupled from the underlying hardware.
I followed up in 2008 with posts on how one would go about implementing such a VERT, and co-authored the paper "Virtual Without Direct Execution" in 2008 to push this idea of emulation based hypervisors, with another paper in 2011 on Microcode Simulation that described a particularly fast implementation of a multiple instruction set direct threaded interpreter.
I made another series of posts in 2010 discussing the impact of the iPad and "the coming wave of ARM devices" (Part 31); how this wave of small non-Intel devices would a game changer, pointing out that a binary translator such as QEMU could be critical to making this happen. A couple of posts later (Part 33) I took a detailed look at the implementation and performance of QEMU and found that QEMU had a lot of problems to solve first in terms of performance and correctness, but problems which I argued then were easily solvable and still claim today can easily be solved.
And since 2012, when the instruction set and specs of the Haswell processor were made public by Intel, I have been making the case (as I hopefully convinced you in my past few posts) that Haswell is a terrific processor to do interpretation and binary translation on which to implement some form of VERT. As I summarized in slides 66 to 73 of my Rise Of The Virtual Machines lecture that I gave to an engineering class at Conestoga College in 2012, I want to see a future where we simplify hardware and emulate everything to the point where emulated code potentially runs even faster than the original bare metal it was written for.
That in a nutshell is what the concept of "dynamic optimization" is and what the topic of this post is today. Dynamic optimization is what I consider to be the Holy Grail of emulation and virtualization going forward. With what I said earlier this week about the Internet of Things, all sorts of heterogeneous devices spanning sub-GHz small cores to highly multi-core monster servers, where is the industry headed to tackle this range of devices in 2015? How close is my wish list to becoming reality?
Dynamic optimization goes mainstream at CGO 2015
The good news I have to report is that there are several companies and organizations heading down the dynamic optimization path these days. In fact, what to me is a surprisingly large and diverse number of players have been making some noise this year - starting with this cryptic message on Transmeta's web site http://www.transmeta.com/ a few months ago that hints of... Transmeta's return?!? (if anyone has any dirt on Transmeta's plans I'd love to find out more!)
A lot of these players were at the CGO 2015 conference in San Francisco this past February, the annual gather of us compiler and code generation geeks, a mouth-breathing geek's fantasy gathering of smart people from the likes of ARM, Intel, Google, Microsoft, Facebook, NVIDIA, and throughout academia. For those who did not attend I will give you a brief summary of some of the cool projects that were presented and discussed.
AMAS-BT keynote address
IEEE conferences like CGO start off with a few days of tutorials and workshops before the main conference begins. This is always my favorite part because it is less formal than the main paper presentations, and I get a chance to meet with and speak with the very people presenting. One of the workshops I like to attend is AMAS-BT (http://amas-bt.ece.utexas.edu/) which is themed around hardware-assisted support for binary translation. It is the workshop where I published emulation related papers in 2008 and 2011 disclosing my techniques for implementing fast 68040 and x86 interpreters.
This year's AMAS-BT keynote address was presented by Ramesh Peri, a principal engineer at Intel. He talked about the past and future of BT (binary translation), and included mention of things like VMware, QEMU, FX!32, and even my own Nirvana dynamic translator that I developed at Microsoft Research. Slides here: http://amas-bt.ece.utexas.edu/2015proceedings/RameshPeri-AMAS-bt-2015%20-%20keynote.pdf
The theme of the keynote was "A tale of two T's", referring to Transmeta and Transitive, two companies that successfully sold commercial products based on BT. In Transmeta's case an x86-compatible processor, and in Transitive's case the PowerPC-to-x86 emulator that allowed Apple to transition to Intel processors in 2006. The conclusions on slide 18 of the talk state that binary translation is a well understood technical problem. I agree! That there are LOTS of myth and misconceptions about BT, I agree in that regard as well, that's why I do this blog series. That BT is active area of research, yes, and that BT has proven its value many times in the past as far as backward compatibility. I agree with all those points, emulation everywhere is my Holy Grail.
So it was interesting that during the keynote Ramesh pointed out that large cloud providers (a couple whose initials start with A) are not taking advantage of binary translation. Does Intel have something in mind? My mind wanders with plausible possibilities...
OpenISA
So let's explore another idea. One of the papers presented at AMAS-BT was on OpenISA, a proposal to have an open (i.e. free) instruction set architecture on which one would use binary translation to run that instruction set on either ARM or x86 hardware. In other words, an instruction designed specifically for the #2 scenario I listed above in my wish list, and my proposal about the VX64 virtual instruction set - a re-encoded common instruction set that applications would be compiled to in order to run on any ARM or X86 device.
Between the keynote and the OpenISA paper, (and there is also the similar project called OpenRISC) there is a common theme of leveraging existing hardware for binary translation of existing (or even virtual) instruction sets.
RISC-V
I went to another workshop (which was technically part of the HPCA conference that was co-located with CGO), this one by UC Berkeley called RISC-V (http://riscv.org/) "V" as in "fifth generation", not "virtual" as I presumed, although I think bought would be appropriate in this case. RISC-V is the work of Krste Asanovic and David Patterson, long known for their CPU research. David Patterson was the co-author of the 1980 paper The Case For RISC, and so not surprisingly co-authored the recent paper The Case For RISC-V which makes yet another case for open (free) simple instruction sets.
RISC-V instruction set consists of only about 40 or so base instructions, all encoded as 32-bit codewords, using a 7-bit opcode field and 5-bit register index fields for a total of 32 registers. This is very similar to PowerPC, MIPS, Alpha, even the internal representation of various emulators. The idea is to have an binary interface that is simple enough it can serve as both a virtual instruction set, or as a simple RISC implementation. So what these folks in Berkeley have done is implemented option #3 of my wish list, they have defined an ISA to not only serve as a virtual instruction set but also be robust enough to tape in silicon and run a real OS. In fact, the RISC-V mission statement in one of their first slides of the workshop was stated simply as this: "Become the industry-standard ISA for all computer devices"
ALL. That mission statement sure sounds like an Internet of Things move!
Here is the cool thing, RISC-V isn't just some proposal on paper, they put their money where their mouth is. RISC-V has actually been taped out in silicon as a real processor called Rocket (https://blog.riscv.org/2014/10/launching-the-open-source-rocket-chip-generator-2/), it has a working GCC compiler toolset that emits RISC-V bytecode, a working Linux distribution compiled in RISC-V, and a QEMU emulator modified to emulate RISC-V. They even provide bootable images of their Linux than can be run on the special build of QEMU. They've built the entire ecosystem to make their argument, wow!
My favorite is the Javascript implementation of the RISC-V simulator called Angel that can run in a Java-enabled browser. Simply click on this link and within seconds you will be running the RISC-V Linux image and toolchain.
As an emulator guy I am in awe an how complete this toolset and ISA specification is, this is exactly the kind of approach that big chipmakers spend years and millions of dollars doing when designing a new processor.
The whole set of RISC-V workshop slides is available here for more details: http://riscv.org/tutorial-hpca2015.html
Now let's look at another potential competitor from overseas...
HERMES
A few years ago I was attending a conference and heard about the Godson-3 processor being developed by China as a strategy to develop a domestic microprocessor market so as to be less dependent on Western chip technology like Intel x86. Godson's instruction set is based on MIPS, a nice simple RISC instruction not unlike the OpenISA, OpenRISC, and RISC-V proposals. Godson runs Linux and Android, and through the use of a modified QEMU binary translator could emulate x86. Slowly.
QEMU (http://wiki.qemu.org/Main_Page) as I pointed out five years ago in Part 33 is just a really lame implementation of a binary translator. It is also a very popular open source project and has some great virtues, such as being able to emulate just about any existing CPU architecture on any other CPU architecture, and comes with a robust set of virtual hardware devices that can be used to model just about any device from a standard PC, to an Apple Macintosh, to an ARM board. Despite its poor runtime performance QEMU is used as the basis of everything from Google's Android emulator to the hardware model for Xen, KVM, and other hypervisors. As I said that same year in Part 31, QEMU could be key to a future world of binary translation based virtualization. Well, somebody has proven me right.
A team from China presented a paper about a project called HERMES (http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7054204&isnumber=7054173) which attempts to fix the performance bottleneck of QEMU. They do this not by rewriting QEMU, but rather by adding a post-optimizer stage to the code that is output by QEMU. QEMU is what I call a cookie-cutter translator, it emits the same little bits of code for the same translated instructions, much like a cookie-cutter stamps out identical cookies. This in itself is a perfectly fine thing to do - I've written several binary translators that use this as a starting point. What HERMES then does is clean out that output, looking for longer patterns of code emitting by QEMU that can be cleaned up, as they showed in one of the slides (and again excuse my lousy cell phone camera):

Using the original output of QEMU for translating ARM-to-MIPS and x86-to-MIPS, these researchers got a 5x speedup on the ARM translation, and 3x on x86. Not bad, and let me tell you why this is a good idea.
In any kind of live binary translation environment such as a Java virtual machine or an emulator, you have trade off latency with performance. The latency of translating a new block of code has to be balanced with the quality of that code. Translate too quickly and the resulting code is terrible (that is QEMU's problem). Take too long to translate and your application will appear sluggish (this is the problem with early .NET and Java virtual machines that tried too hard to get it right the first time). The correct approach is to use a multi-pass optimization strategy, as some Java hotspot VMs now use. The first pass do either a simple jit translation or even just interpret the code. Use that keep latency low, but keep track of what translations execute a lot, a.k.a. "hot blocks". Then go an re-translate the hot blocks using a higher latency higher level of optimization. Or as HERMES does, don't re-translate, just post-process and save a bunch of redundant work.
As other research papers have suggested in the past, this can even be pipelined, where extra (idle) threads on the host CPU can be used for these further levels of optimization, keeping the main thread at low latency. I like where this is going...
As is now becoming standard at these conferences, Google was all over the place, from recruiting booths, to workshops such as the LLVM tutorial, to papers on binary translation. Derek Bruening, the developer of the DynamoRIO instrumentation framework, formerly of VMware but now at Google, presented a paper called "Optimizing Binary Translation of Dynamically Generated Code" on similar post-processing of jitted code (such as the output of a Java VM) in order to achieve gains of up to 6x in performance.
A second paper presented by Google entitled "MemorySanitizer: fast detector of uninitialized memory use in C++" discussed using binary translation to discover bugs due to uninitialized variables. This is not a new idea, such plug-ins have been developed over the years for Nirvana, Pin, and DynamoRIO. In fact, the translators described by both papers were implemented using DynamoRIO. My main takeaway of this second paper is that this analysis can be done with about a 2.5x slowdown in execution speed.
That's a pretty interesting number, because for one thing, it is vastly faster than QEMU runs at, demonstrating that binary translation is not a slow technology, QEMU is just implemented poorly. Second, 2.5x is within the realm of usable emulation. Let's say you have some mission critical application that absolutely must not be exploitable because of say, stupid uninitialized variable bugs.
Derek Bruening and his collaborator Qin Zhao are also the authors of a CGO 2010 that I mentioned before called Umbra (http://www.cgo.org/cgo2010/talks/cgo10-QinZhao.pptx) where they similarly used DynamoRIO to sandbox memory at a 2.5x slowdown. So now they've demonstrated that not only can you merely sandbox memory, you can detect defects such as uninitialized memory accesses on-the-fly.
That type of live analysis of executing code is one of the biggest potential uses of dynamic optimization in the war against malware and hackers. Is it worth running code at half the speed if it means stopping potentially catastrophic exploits from taking place? I'd say so.
And if you read the paper, their benchmarking was performance on old generation Intel Westmere micro-architecture - the Xeon W3690, a dinosaur compared to today's Haswell micro-architecture - and thus their work is not even exploiting the binary translation assistance that Haswell offers. I claim that as more binary translators start to take advantage of Haswell's AVX2 and BMI and TSX extensions, we will see these sandboxing overheads drop to below 2x if not below 1.5x. That kind of overhead would be worth the added security in my opinion. I wonder if this is what the Intel engineer was eluding to in pointing out that major cloud providers do not take advantage of binary translation.
Recall also that Google has been using emulation to do defect detection for years. Back in April 2013 a couple of Google engineers published the paper Bochspwn- Exploiting Kernel Race Conditions Found via Memory Access Patterns (https://www.youtube.com/watch?v=3va_1tTWQjw) in which they used the plain old Bochs x86 simulator, yes Bochs, to find dozens of security holes in Microsoft Windows, which led to a slew of Windows Update patches in the spring of 2013.
Along those lines may I recommend an excellent book called Automatic Malware Analysis - An Emulator Based Approach which similarly describes how to use the QEMU emulator to discover exploits. Between DynamoRIO, Bochs, QEMU, and other tools, the bad guys have no shortage of weapons to attack your code, and it seems to me that only Google is pro-active in fighting back.
As I keep saying, Google is putting together a scary good team of static and dynamic compiler experts, CPU experts, emulation experts, and virtualization experts. I can list over a dozen former colleagues in this field from Microsoft, Intel, and Amazon who I now know to be working at Google, even my old manager from the Nirvana project, not to mention industry experts such as Derek Bruening. Between their work on LLVM, Android, Java, DynamoRIO, I can only suspect (and hope!) that Google is building some kind of "emulate everything" software stack that is hardened for security, which would be an extremely competitive advantage for example in the area of trustworthy cloud computing.
NVIDIA's Denver CPU
But one company gave a presentation just weeks after CGO at Stanford University in March 2015 to really up the bar. If you recall back at CES 2011, NVIDIA announced a project called Denver, their entry into the ARM market with what they claimed to be a "high performance ARM core". https://www.youtube.com/watch?v=oyNgyq7sK_8
Lots of companies make such claims, so I didn't pay much attention to this until earlier this year, when Nathan Tuck of NVIDIA gave this presentation at Stanford University to give details on Denver: https://www.youtube.com/watch?v=oEuXA0_9feM
I find this presentation to be so relevant and important that I am embedding the video below, about 75 minutes long, and would highly urge you all to watch it in its entirely.
What NVIDIA is releasing is not a hand wavy paper or some academic research project, this is a real product that is going to go into real devices. They have developed a chip that is not just ARM compatible, it is a non-ARM architecture that uses dynamic optimization to emulate a 2+ GHz ARM processor. They built this using the Transmeta technology NVIDIA licensed years ago, and extended Transmeta's work to support both 64-bit and multi-core. This is profound, because don't let the ARM part of it fool you. NVIDIA built this on top of Transmeta's technology that was already emulating 32-bit x86. I see no reason, in fact I expect, that NVIDIA will some day, maybe this year, maybe next year, announce that "oh by the way, we updated the dynamic optimizer so that your Denver chip now runs x86 code".
Imagine a 64-bit multi-core processor that can boot either as an ARM64 or as 64-bit x86 chip, possibly even run code of both instructions set at the same time. A hybrid CPU that could be dropped in to any tablet, any laptop, any server. Wow! RISC-V, you've been served!
This is not an absurd line of reasoning. If you look at the public information that NVIDIA has released about the architecture of Denver, such as this slide from Anandtech's site: http://images.anandtech.com/galleries/3847/Screen-Shot-2014-08-11-at-3.49.42-PM.jpg you can see that Denver is a 7-wide pipeline, which is much wider than the typical ARM, Atom, or legacy Core architecture. ARM code has a typical IPC rate of about 0.8 to 1.2 on real-world code, well below the 1.5+ that modern Intel architectures now deliver. So there is headroom built in, headroom to handle the extra instruction overhead of a binary translator execution engine (such as when needing to look up a hash table to map the target address of an emulated jump). This is not the core of a simple ARM processor, this is a core with a lot of extra headroom built in for something.
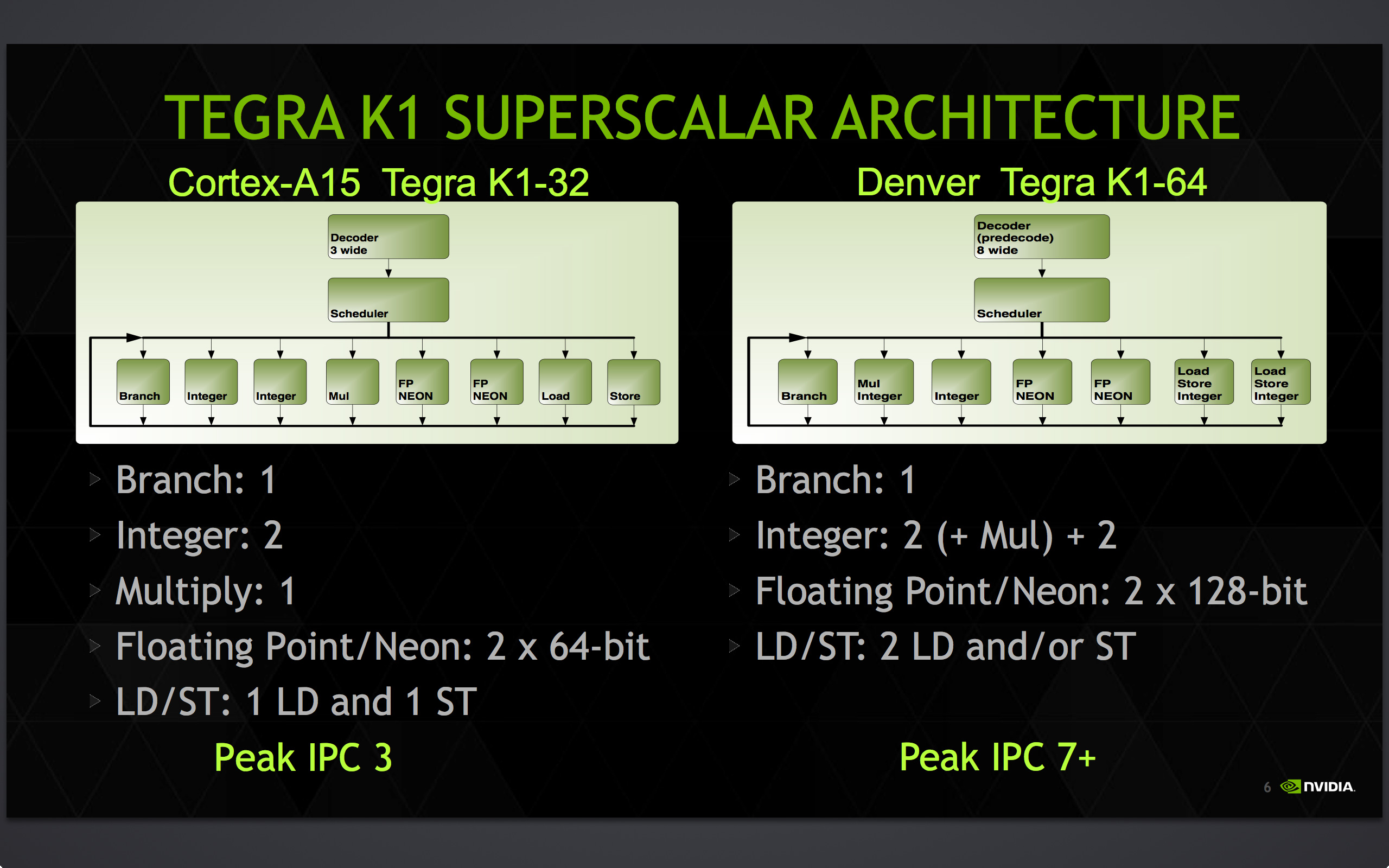{kind=link}
To think that NVIDIA has spent 4 years or more developing Denver to then just stop at ARM, that's unlikely. Perhaps PowerPC? But my bet is x86, which then instantly makes them a player for next generation of game consoles and cloud servers.
Haswell (and successors)
Let's pause and summarize, there are at least three if not four (if we are to take Transmeta's cryptic message seriously) different custom CPU projects in development that could potentially implement a hybrid ARM/X86 chip using a software based VERT dynamic optimization mechanism - Denver, RISC-V, Godson-3. But does this really require a new custom chip? Google has demonstrated that the upper bound of translation overhead on old 2010-era hardware is 2.5x, no custom hardware required. And I claimed above that 2.5x could be brought down to 2x or even 1.5x or better using more modern processors.
There is one chip already out there that is suited to doing this, you might have heard me mention it, like, a bzillion times - the Intel Haswell. <grin>
Haswell and its die-shrink Broadwell have the transactional memory capability that was one of Transmeta's secret sauces to emulation. Haswell has the 7-wide CPU pipeline help hide the virtual machine overhead by utilizing what would otherwise be unused ALU or memory ports. What other chip, that is specifically design for BT, has a 7-wide pipe? NVIDIA Denver. Each can perform up to four ALU operations per cycle. Each can perform two memory loads per cycle. Haswell can even throw in a memory store to boot. Haswell is even out-of-order, while Denver relies on the translator to schedule instructions.
It is obvious to me looking at the designs of the two processors, and contrasting Denver's pipeline with Haswell's: http://files.tested.com/photos/2013/06/03/48693-haswell_micro1.jpg that Haswell can outperform Denver at equal clock speeds. Therefore Haswell, with proper binary translation software, could virtualize both ARM and x86 at decent speed entirely using BT, certainly faster than Denver.
{kind=link}
Haswell's two main disavantages compared to what I discussed above are cost and power consumption. Haswell is not ready for use in say, a cell phone, but that is where a future iteration that cuts clock speed, shrinks the die further (like Broadwell) or combines features with Atom could hit the mark. I know what Haswell is capable of, and the fact than an Intel employee would bring up dynamic optimization during the AMAS-BT keynote with reference to the cloud again hints that they are up to something in the server space.
Language VM Translators
So far I've listed a number of dynamic optimizers that operate the ISA level - they re-translate machine code. There are also binary translators that are used for high-level languages such as PHP, Java, and C# to optimize a single user-mode process at a time. These are the high-level language translator such as Facebook's HHVM, of course Java, and the CLR (Common Language Runtime) in .NET. The three I list below are open source translators on GitHub that are worth a look, and I have to say, kudos to both Facebook and Microsoft for opening up and open sourcing their runtimes.
HHVM
https://github.com/facebook/hhvm/
My understanding of HHVM is Facebook developed it to replace an older, much slower, PHP execution engine. Facebook engineers chose to write a new engine from scratch instead of optimize the old one; perhaps a similar fate need to fall on QEMU's clunky TCG translator. Looking at the code for the HHVM back end (not the PHP front end, since quite honestly I wouldn't know PHP if it was carved into my desk) I am little surprised their selection of x86 machine instructions falls into the usual early-2000's SSE2 instruction set. A former manager once impressed on me that if you want to learn about the architecture of a body of code, just look at its test suite. So in addition to looking at the emitter I looked at the unit tests for the emitter. And sure enough, if you look at hphp/util/test/test.cpp in the HHVM repository, they test for the usual stock set of 64-bit integer x86 instructions, with a sprinkling of SSE1 32-bit floating operations and SSE2 packed integer operations. This is code designed to run on 2003-era AMD Opterons, not 2015-era Haswell Xeon v3 servers.
So Facebook, if this is the code you're running your server back end on, you've got a long way to in terms of shaving cycles.
CoreCLR
https://github.com/dotnet/coreclr
Microsoft has come a long way in the past two years since the days of Steve "OSS is a cancer" Ballmer. Between their foray into ahead-of-time compilation with .NET Native, releasing the free Visual Studio Code editor for Linux and Mac OS X (https://code.visualstudio.com/Download), and their decision to open source the CLR itself, this is bold new Microsoft. Had they open sourced .NET from day one, the project Mono would never have been needed.
Poking around CoreCLR's sources, I am pleased to see support for both AVX and AVX2 code emission, include Haswell's very powerful new BROADCAST[B|W|D|Q] instructions. This is definitely capable of targeting current generation processors.
Project LLILC
http://blog.llvm.org/2015/04/llilc-llvm-based-compiler-for-dotnet.html
https://github.com/dotnet/llilc
LLILC (pronounced "lilac") is the most shocking announcement from last week's BUILD conference. This really embraces the cross-platform support ideology by taking the CoreCLR above (which is a Windows-only WIN32 codebase that targets only the processors that Windows run on) and saying let's replace that with the more robust LLVM code generator that can target anything. The choice of LLVM is logical - it has wide industry support, targets just about anything (not just ARM or x86), and as I pointed out on Wednesday, produces damn impressive code compared to GCC or even Visual Studio's c2.dll back end.
Microsoft is already adopting Clang (the front-end counterpart of LLVM) as their Objective C compiler front end. So is it only a matter of time before Clang becomes Microsoft's standard compiler front end and much like Apple and Google have already done, Microsoft embraces that as their main compiler?
So let's take a look at the LLILC design, I copied these two diagrams below from their web site. LLILC is designed to kill two birds with one stone - the static ahead-of-time pre-compilation model (presumably to replace the .NET Native compiler they announced last year), and the usual just-in-time JIT compilation model similar to the behavior of typical .NET and Java virtual machines.
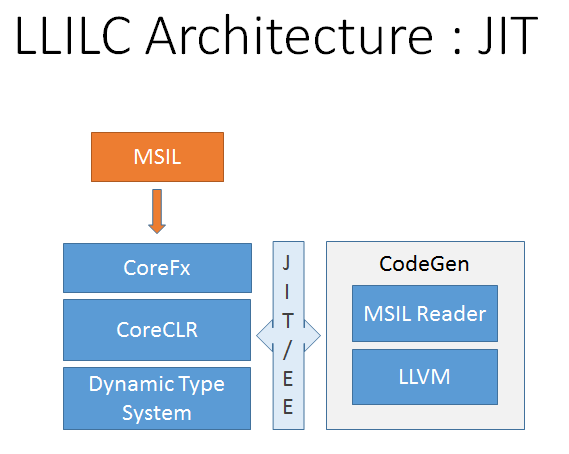
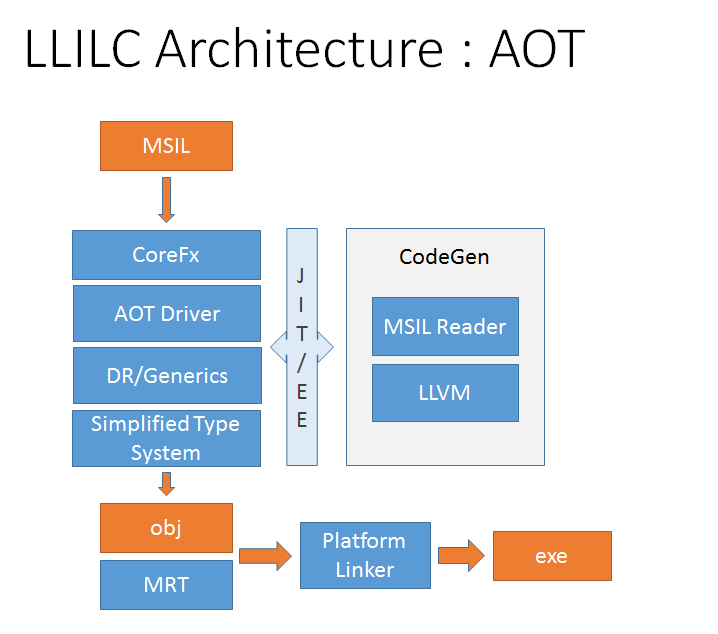
In theory, using LLVM in both offline and online modes will generate similar highly optimized code. But I have two comments about this:
First, LLVM is very heavyweight compiler. It makes for a great offline compiler for C/C++ where compilation time is not of concern as much as the resulting compiled code. However, whenever I have read about people trying to, for example, replace QEMU's TCG translator with LLVM as a JIT compiler, the results have been mixed. The slower compilation time of LLVM compared to a fast-JIT like TCG adds latency at run time and can make an app appear sluggish. For short running benchmarks or transient code this can mean that LLVM's translation time defeats any benefit of better code that it generates. Unless LLVM has tricks to JIT fast, the ahead-of-time use case seems like the more logical one for now, must as AOT is now the default in Android. AOT would also work better on a dynamically optimizing processor such as Denver by avoiding the double-jit problem.
So my second comment is that there is at least one scenario (if not two scenarios) missing from these diagrams. Java supports a third mode of execute - pure interpretation for low-memory devices that lack the RAM to do JIT at run time and might even lack the memory or disk footprint necessary to invoke LLVM as an AOT compiler (think embedded device where everything including the CoreCLR and applications are in ROM and the amount of writable RAM is very small). And alternative to an interpreter would be a much simpler JIT engine, possibly like the one used by CoreCLR or the existing .NET, that emits decent code with some bounded memory footprint for compilation.
The other use for interpretation, as I commented about in the HERMES section, is to identify the set of "hot blocks" and reduce my amount of invocations of the LLVM heavyweight JIT. Such an in-between solution between pure AOT and heavyweight JIT I feel is needed to fill in the roadmap and truly handle the full spectrum of "Internet Of Things".
The End
Nothing more I will teach you today. That concludes this week's Star Wars themed trilogy on hardware, static compilers, and dynamic optimizers. I trust you found at least some of it mildly educational. I would really encourage everyone to click through on the various links and videos above and look at what was presented, this _is_ the future of computing.
To summarize this trilogy of posts I have:
- Given you some further detail on the vast improvements to Haswell and Broadwell micro-architecture and ISA architecture over past generations of Intel processors and argued for a serious new focus on code quality improvements.
- Demonstrated some fundamental shortfalls of today's x86 compilers, more than 20 years after 32-bit x86 became commonplace, but also showed that today's compiler toolsets such as Clang/LLVM, GCC 5.1, and Visual Studio 2015 are vastly improved over their predecessors.
- Introduced you to the new batch of ahead-of-time compilers for Java and .NET and explained that with all these static compiler improvements there is still a need for dynamic optimization to handle the 20 years of inefficient legacy code.
- Discussed the problems of the fragmented computer market of the 1980's and how today's availability of open source development tools, cross-platform compilers, and fast emulators can avoid such fragmentation today.
- Explored security and defect detection, and how dynamic optimization can play a major role in live analysis of running code to stop defects before they cause damage.
- Highlighted some of the exciting technology coming from the likes of NVIDIA, Google, Microsoft, Facebook, potentially Intel and Transmeta and a number of academic institutions, in the field of dynamic optimization and low-cost RISC designs for the Internet Of Things.
What the ultimate fate of RISC-V will be, what Transmeta's secret new plan is, what Intel was hinting at during the AMAS-BT keynote, whether China's domestic processor will threaten Intel, or whether NVIDIA will reveal x86 support for Denver, I do not know. I am a curious engineer taking time off between day jobs amusing himself by connecting the dots from all of this public information that I have pointed you at. Whatever the outcome, I have a feeling the next year or two should be quite an exciting time in the field of whole-system virtual machine dynamic optimization. It's about time! Compiler technology had been stagnant throughout the 2000's, while hardware virtualization has been an unnecessary evil (initially created to work around flaws in AMD64) whose existence I have opposed from day one. Virtualization - just like emulators and high-level language VMs - should be implemented using binary translation, period.
Man I get cranky sometimes! On a lighter note, having just visited it recently may I recommend to any visitors to Seattle this summer to visit the Star Wars costume exhibit at the EMP (next to the Space Needle). Well worth the trip down memory lane as we wait for the new movie.
Also another great attraction in Seattle is Paul Allen's Living Computer Museum, where fully working computers such as the Apple II, Commodore 64, IBM PC, and other old dinosaurs are on display.
I will be in Portland this June for annual ISCA conference, and then will come back with a new blog posting after the final launch of Windows 10 and Visual Studio 2015 to update my progress on Gemulator 10 and SoftMac 10 for release on Windows 10 devices. Have a great summer until then.
If you have any questions or comments, you can of course email me any time at: darek@emulators.com