NO EXECUTE!
(c) 2010 by Darek Mihocka, founder, Emulators.com.
July 12 2010
Now that the World Cup is wrapped up I will jump right in to this week's main topic of discussing the recent ISCA conference and begin my multi-part discussion about QEMU.
ISCA 2010 Goes to France
Late last month I had the pleasure of travelling to the beach town of St. Malo in France for this year's ACM/IEEE ISCA conference. ISCA of course being one of the main annual computer architecture conferences in the world. It is an incredibly geeky and interesting conference to go to, one I would highly recommend to anyone interested enough in computer architecture details to be, say, reading this blog. Very rarely do members of the public get the opportunity to meet and chat with some of the very people who have designed the very computer chips that we use every day, and ISCA is one of those times. A pleasant location such as pre-Olympics Beijing or beautiful St. Malo doesn't hurt either. How do I even begin to describe how delicious and relatively inexpensive the food in the various St. Malo eateries was other than to say you just have to go to St. Malo and experience it for yourselves. Be prepared to eat a lot of crepes and galettes, they are delicious!



I was originally headed to ISCA to present a couple of papers I co-wrote for this year's AMAS-BT conference workshop (http://amas-bt.cs.virginia.edu/) on the topic of what else, binary translation based emulation. It was two years ago in Beijing that I presented my "Virtualization Without Direct Execution" paper at the first AMAS-BT workshop, and expected to be presenting on June 20th. But unfortunately I didn't make the cut this year, not to mention I showed up on the evening of the 19th expecting the workshop to be on the 20th only to find out it had been rescheduled for earlier on the day of the 19th, oops! So I enjoyed ISCA as a mere tourist and soaked up many of the presentations and lectures in addition to all the crepes and galettes.
Following the 2008 conference I did a brief write-up of what I saw in Beijing and what topics were discussed, in Part 20. I unfortunately did not get a chance to attend the 2009 ISCA conference in Austin due to work and travel conflicts at the time, so going back to ISCA two years later I wondered what new topics would be discussed, what new interesting papers would be presented, and what cool words of advice the guest speakers would have this time around. A recurring theme of many of the presentations this year was to remind us to look back at computer history; to look back at what has been tried and maybe forgotten in the past before just blindly trudging along into the future.
The first lecture on the morning of Monday June 21 was a keynote by Bill Dally who is currently the Chief Scientist at nVidia and brings many decades of experience from academia and industry. Bill's keynote was entitled "Moving the needle" in which he talked about the "architecture funnel"; the various stages along which ideas and concepts get turned into real world product. At first you have many many ideas, and as you refine them you need to trim those down and kill the bad ideas early. Don't let them get too far into development. But also, do not discard the things that you learn from those failed ideas. Use the data from the failures to feed back into the development of the other ideas.
Obvious? Well, maybe not to everyone. Consider the Microsoft Kin phone, the offshoot of an expensive buyout of a company called Danger two years ago (http://www.wmexperts.com/articles/microsoft_buys_sidekick_maker.html). In February 2010 Microsoft announced the upcoming series of new Windows Phone 7. Makes sense, their Windows Mobile 6 phones have been around for a number of years and grossly in need of an update. But was it based on Danger technology? No, so then in April 2010 out of the blue Microsoft releases the Microsoft Kin phone, not a Windows Phone 7, in fact not a phone anybody expected. I barely had time to understand what the Kin was and why I needed it before Microsoft pulled the plug on it, citing the need to focus on development of... the Windows Phone 7. Duh? One can only imagine the millions of dollars spent buying out Danger and the two years of development that went into the Kin, the millions more in marketing, for a product that ended up being on the market for all of 2 months. They pulled another Microsoft Bob, putting out a product that nobody really needed or expected, that conflicted with development of other similar products, killed it, and just wasted a lot of effort. My guess is that they shipped something for the sake of justifying the expensive buyout from 2008, logical or not, throwing good money after bad. Did Microsoft "move the needle" in this whole fiasco? Absolutely not. People are buying up new iPhones like crazy and the rest of us are stuck paying hundreds of dollars for Windows and Office to finance the buyout whims of Microsoft's reckless vice presidents.
Bill Dally spoke based on years of product development experience, and he kept stressing the need to kill bad ideas as soon as possible. Don't cling on to them for irrational reasons, don't proceed without good data. Another key insight he gave was to point out that teams can't work in isolation. If you are putting together a software stack such as an operating system, or a software/hardware stack as shown in the slide pictured below, you cannot just tweak one component in isolation. Anything you change will affect everything else. Seems obvious, but look at how many product integration problems have occurred in Windows with "DLL Hell" as people upgrade one component without regard to the downstream effects on other components.

This is one of my peeves about the x86 instruction set, that the evolution of the hardware and its adoption by mainstream software sort of happens independently instead of the two sides working together. So consumers regularly end up buying computers with processor features (64-bit, SSE4, etc.) that aren't even utilized by most software until about when that computer becomes obsolete. For example, millions of PC users and Mac users have purchased 64-bit "capable" systems in the past 6 or 7 years and never yet even installed a 64-bit operating system. Still using Mac OS X Leopard or Windows XP SP2? You're not running 64-bit code but you probably paid for that capability.
Another great suggestion Mr. Dally made was to stress that we should not tie ourselves down with artificial design constraints. For example, the laws of physics present hard design constraints which cannot be modified. On the other hand, with man made constrains such as instruction set architectures (ISAs) many times people artificially limit themselves by trying to adhere to some specific ISA when in fact that is not set in stone. An example of this is the opposite approaches that chipmakers Intel and nVidia go about handling graphics. Whereas Intel has been building upon the same x86 instruction set for three decades now and is building new graphics extensions on top of x86, nVidia takes the approach of changing the graphic processor's ISA regularly and hiding that from the user via the Cuda compiler. As I have mentioned in previous postings, that similar approach of hiding an ever changing ISA trick was pulled off by Transmeta in the 1990's which maintained perfect x86 compatibility without implementing the x86 ISA in hardware.
Along the lines of not artificially constraining oneself, another really great lecture was by Chuck Thacker of Microsoft Research (Silicon Valley Campus), who forty years ago helped develop the graphical computer interfaces that we all use today. Thus no surprise then that he is deservedly the recipient of this year's Turing Award. It was certainly a pleasure to hear him present "Improving the Future by Examining the Past", where he walked the audience through a thought experiment of how would we design computers differently today for the 21st century if we had it all to do over again based on all the knowledge of the past few decades. Of the half dozen or so design choices he discussed, one for example was to question whether or not we truly need demand paged virtual memory. Is the complexity that virtual memory adds to hardware worth the cost, given that most laptops and home computers today come equipped with at least 4 gigabytes of memory and even cell phones have on the order of a gigabyte of memory? Another of the almost untouchable pillars of modern computing that he called into question is the need for interrupts, which he pointed out contributes to a lot of complexity not just at the hardware level but the software level as well. Mr. Thacker suggested re-examining every design decision in microprocessors today and redoing many of them and I fully agree.

I will be the first to admit that I was salivating and hyperventilating listening to these two men speak, because what they say rings true with my own experiences of the past 30 years working on compilers, virtual machines, and software applications. Hardware and software are getting more complex every year and yet reliability seems to be going downhill. I recommend going back and re-reading my postings in Part 3 ("Ten Fixes") from three years ago, where fix #2 of my ten proposed fixes for x86 is, you guessed it, to eliminate all hardware based memory translation. Follow by my rule #3 to eliminate interrupts and exceptions just as Mr. Thacker suggest. That posting, and the following posting in Part 4 ("Hardware Virtualization Trap"), I listed in detail various hardware design decisions made over the past few decades which I proposed be scrapped given what we know today about security issues, virtualization needs, and microprocessor performance bottlenecks of real world scenarios.
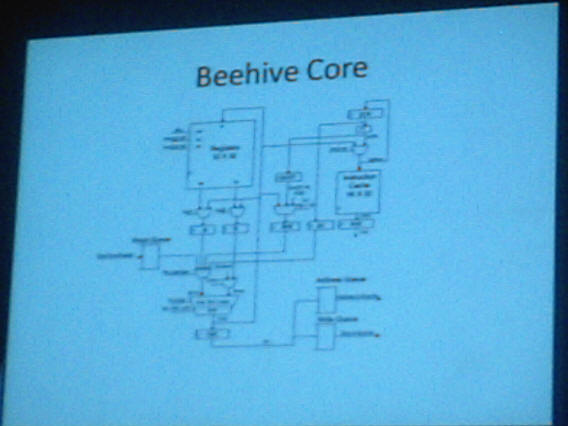
What pleasantly surprised me was finding out that Microsoft Research is going a lot further than just suggesting this simplification of hardware. Mr. Thacker went on to describe a prototype low-power CPU core being developed at Microsoft Research called Beehive, which suggests to me that Apple (with their custom ARM variant in iPad) may not be the only operating system and applications vendor to be venturing into chip design these days.
One of the first research papers presented was from Stanford University entitled "Understanding Sources of Inefficiency in General Purpose Chips". They presented data to show how around 90% of the energy consumed by a microprocessor is wasted as overhead such as moving data around and fetching instructions. The authors even quantify the energy cost of moving a single bit of data one millimeter, and point out that the fewer bits you need to move around, the lower the energy overhead. This explains why most mainstream desktop processors to get maximum speed will break down an x86 instruction into simpler micro-ops, yet energy efficient processors such as the Intel Atom (http://download.intel.com/design/chipsets/embedded/prodbrf/Atom_Product_Brief.pdf) use instruction fusion, also called macro-op fusion, to minimize the number of bits moving through the pipeline, thus saving energy. The authors show that the cost of fetching an instruction from the instruction cache often greatly outweighs the energy cost of the operation itself. In other words, it wastes more energy to fetch an ADD instruction than to actually perform the ADD operation.
Not only does data like this scream for an instruction set redesign, but keep in mind my observations from three years ago in Part 5 ("Rebooting the 64-bit Specification") that due to lack of opcode space newer x86 instruction encodings need more code bytes to encode. Therefore as Intel and AMD add fancier and fancier new instructions those instructions also consume disproportionally more energy. This is a good argument to either scrap x86 instruction set altogether or re-encode it in a more compact form such that more frequently used operations are encoded using fewer bytes. No wonder that in ARM processors, the instruction set was recoded a few years ago into the denser ThumbARM instruction set used on very low power devices. Ironically, code density was one of the original design goals of the 8086 instruction set thirty years ago, i.e. to essentially Huffman encode the 8086 instruction set in order to achieve higher code density than comparable RISC instruction sets. This concept only works for as long as you re-encode the instructions each time a substantial new set of instructions is added, something that AMD (and later Intel) failed to do with the 64-bit AMD64/IA32e instruction extensions, as well as with MMX and SSE (what I referred to as the blown opportunity to simplify 64-bit x86 back in my Part 6 posting).
Stanford University's paper's nicely shows that there is potentially an order of magnitude power reduction possible in general purpose processors using techniques such as reducing overall code size by merging instruction operations and small dense instruction encodings. Which if you don't buy into my old postings from 2007 nicely goes with Mr. Dally's point of not artificially locking yourself in to a specific instruction set simply because that is the instruction set you used before.
Another interesting paper was presented by employees of VMware entitled "The Impact of Management Operations on the Virtualized Datacenter". I love reading papers from VMware - such as Keith Adams' paper comparing BT versus VT based virtualization and Ole Agesen's paper on optimizing binary translation of RET instructions - because VMware does their research on real code, in real product, running real workloads. Too many academic research papers take the easy route of presenting data on the same dozen or so boring SPEC2000 benchmarks and rarely on real Windows or Linux code that you and I actually run every day. In this paper, VMware analyzed the real-world characteristics of large datacenters, much as what would be used for cloud computing infrastructures, and quantified how the maintenance and migration of virtual machines around a datacenter adds a considerable amount of bursty I/O traffic on top of any traffic being generated by the actual virtual machines. I was introduced to the concept of the "boot storm", which is the sudden spike in disk and network traffic that occurs when a large number of virtual machines are booted at once. As more servers and web sites are moving "into the cloud" this will be an area of research of great interest not only to hardware designers and hypervisor developers, but to general software developers as well who care about the performance of their applications in the cloud. You won't be able to just write software in isolation without thinking about its impact "on the cloud", which admittedly even I, long time software guy, know far too little about.
Another thing I was completely ignorant about are non-volatile resistive memories, which is flash-like memory based on a new type of electronic component called the "memristor". Similar to existing flash memory, resistive memory can only reliably be written to so many times before bits start to fail, on the order of about a billion writes. Microsoft Research presented a paper entitled "Use ECP, not ECC, for Hard Failures in Resistive Memories" on how one would perform efficient error correction on such memories. Regular ECC error correction such as used in DRAM memory can detect a single-bit error in a byte of memory and then overwrites that byte with the corrected data. Such an approach does not work well if the bad bit is permanently defective as will be the case with memristors. The paper showed a simple and clever scheme whereby the error correction data is appended as a series of integers which specify the location of the bad bit. Every 32-byte block of resistive memory would have a certain number of such extra space available to add this correction data for several bad bits. The paper goes on to explain how even errors in the error correction data itself could be detected and handled. Neat!
There was a fascinating paper from Ghent University in Belgium called "Modeling Critical Sections in Amdahl's Law and its Implications for Multicore Design", which in layman's terms was a study to determine how best to divide up the real estate on a piece of silicon in order to get the best performance of multi-threaded code. Should the core be divided up into many many tiny cores (along the lines of tiny in-order Atom cores), or into a small numbers of very fast out-of-order large cores (such as Core 2 or Core i7 today), or some heterogeneous mixture of the two which allows some large cores to handle interrupts and locks (i.e. critical sections) very quickly while smaller cores handle non-contentious threads? What the modeling found is that you do not want to make the small cores too small and simple, that you can actually achieve faster throughput by having a smaller number of medium sized cores along with the few large cores.
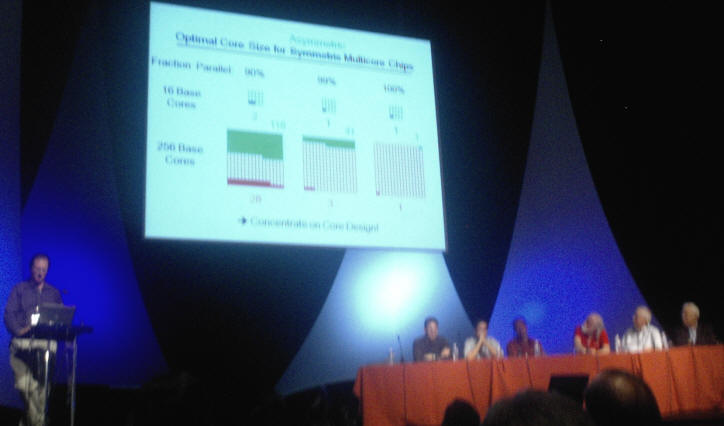
With apologizes to Ghent University if this is too simplistic I will try to rephrase their findings a different way in the form of an analogy. Let's say you are setting up a delivery company and you have enough resources to operate 4 large delivery trucks, or a fleet of 40 cars, or a fleet of 400 bicycle couriers, or some mixture where 10 bicycles cost as much as one car and 10 cars cost as much as a large truck. Would you spend your money on just the 4 large trucks (analogous to the 4 large cores of today's quad-core processors)? Of course not, because for small packages you are better off using cars or bicycles and to be able to deliver more than 4 packages at once. But you would not want your fleet to consist solely of 400 bicycles either (the many small cores on a die approach) because you probably would not utilize the whole fleet on any given moment so you would be unable to handle large deliveries efficiently. The heterogeneous approach is to have maybe two large delivery trucks and the rest in cars or bicycles. What the results of this paper suggest is that you are better off putting your remaining resources into 20 cars than 200 bicycles - i.e. go with fewer medium-sized delivery vehicles than too-many too-small vehicles. Interesting food for thought. Something for chip designers to ponder as they try to find that sweet spot that delivers maximum single threaded performance and overall multi-threaded throughput.
Back to the Intel / nVidia rivalry. There was one paper Intel presented on the last day that was aimed squarely at nVidia. Entitled "Debugging the 100X GPU vs. CPU Myth", a number of Intel employees made the case that for throughput computing involving very highly threaded applications it is a myth that GPUs (such as the nVidia GX280) are a hundred times, even a thousand times, faster than CPUs (such as the Intel Core i7). GPUs have the advantage of being able to perform hundreds of identical operations at a time, and well suited for things like graphics processing where you operate on thousands of pixels of data at a time. Intel, as with AMD, has tackled the graphics throughput issue by adding the MMX and SSE SIMD instruction set extensions, over the years widening and widening the data width of these operations in order to be able to perform more and more floating point operations and integer operations in a single clock cycle.
Intel's paper presents data to make the case that on average the Intel CPU is "only" 2.5x slower than the nVidia GPU, not 100x. I stress "on average", because in some cases it will be up to 14x slower than the GPU. A kind of "hey, we're just a little slow" message. This backfired on Intel, as the presentation was quickly picked up by the media who had a field day with it:
http://www.neoseeker.com/news/14204-intel-admits-gpus-are-faster-than-cpus/
The story might end there, except some other people did some digging as to what the basis was of the 100x claims in the first place, and found that nVidia was unfairly crippling the CPU version of its tests by running certain benchmarks in purely single-threaded legacy x87 mode instead of utilizing the vector SSE instructions:
http://techreport.com/discussions.x/19216
http://realworldtech.com/page.cfm?ArticleID=RWT070510142143&p=1
So it seems both companies have egg on their face. It's a little infuriating actually, that all these engineers are wasting their time on what are nothing more than silly PR stunts. In my brief stint at Intel I worked in a totally different group and had nothing to do with these results, but it seems Intel and nVidia are having the same kind of childish pissing match that Microsoft and IBM did twenty years ago in the days of the Windows vs. OS/2 "your software is buggier than my software" wars. Sigh. This matter will go another round soon as nVidia promises turn on the SSE support by default in the next release of its PhysX engine:
http://www.geeks3d.com/20100711/cpu-physx-x87-sse-and-physx-sdk-3-0/
Nevertheless, ISCA has a little bit for everyone, for hardware people, for software people, for end users, and what is presented there has real relevance to all of us who own and use computers. Next year's ISCA conference (http://isca2011.umaine.edu/) is being held June 2011 in San Jose California and I certainly plan to attend and re-submit my papers. And I suggest everybody in the industry make plans to attend and learn something new. Given the location, there is no excuse for every engineer in Silicon Valley not to attend.
A Paper Without Data - Is This What They Teach The Kids Today?
One ISCA paper I was not particularly impressed by was a paper from Princeton University entitled "NoHype: Virtualized Cloud Infrastructure without the Virtualization" ( http://www.princeton.edu/~szefer/publications/isca10.pdf)

The premise of the paper sounds interesting indeed. Virtual Machine Monitors ("VMMs" or what are commonly referred to as "hypervisors") can and do have security holes, which if breached could potentially allow the leakage of data between virtual machines. This is not unlike security issues in mainstream operating systems such as Windows and Linux where it is possible to find exploits where one compromised process takes control of another process or read files and personal data that should be off limits. Virtualization adds a level of indirection to this, where now such exploits could span virtual machines, i.e. between two entirely separate operating systems that should be isolated from each other.
That virtual machine exploits are potentially the next big thing for malware is not a new fear. The idea of VM Rootkits was discussed by mainstream media more than 4 years ago (http://www.eweek.com/c/a/Security/VM-Rootkits-The-Next-Big-Threat/) and is a real threat. I have devoted several blog postings in the past pointing out the stupid one-off attempts tried in both hardware and software over the years to tackle security issues, such as the useless "NX" Bit for which this blog is named, and my argument has always been to say stop adding junk on top of junk. It is why in my "10 Fixes" posting I argued the case to just get rid of hardware memory protection altogether, because as many layers of memory protection that AMD and Intel have piled up over the years, it obviously still does not work securely.
And as I discussed two years ago about a product that got a lot of negative press attention, the AMD Phenom processor had a horrible hardware bug which effectively rendered virtualization useless:
http://www.dailytech.com/Understanding++AMDs+TLB+Processor+Bug/article9915.htm
Installing a VM Rootkit on, say, a single laptop computer to steal one user's data is one thing. With the advent of large virtualized datacenters and cloud computing such as discussed by that VMware paper I just mentioned, a virtualization exploit could potentially take down or take over hundreds of machines. What if a datacenter had deployed with hundreds of these defective AMD processors, oops?
The authors of NoHype made a radical claim: that they can eliminate the security threads of virtualization by eliminating the virtual machine hypervisor itself!
That is a bold claim, based on the logic that since modern hypervisors might contain, say, 100000 lines of code, that large amount of code has to be a security threat. As proof they cite some VMware and Xen exploits from earlier versions of those products. Therefore, the logic follows, eliminate that code! By eliminating the hypervisor, you eliminate the ability to over-commit memory, to over-commit processor cores (i.e. the practice of hypervisors of putting two or more virtual machines onto a single core), and you replace the virtual hardware emulation which most hypervisors provide with direct access to the actual hardware on the host machine. This is known as "I/O passthrough" or "hypervisor bypass" and is implemented to varying degrees in most virtual machines such as VMware Workstation and VirtualBox. The most common example that most people are directly familiar with would be USB support, where devices plugged in to the USB port when a virtual machine is active get directly sent through to the virtual machine. In the NoHype implementation, every device is directly accessible to the virtual machines, for example by segregating access to hard disk drives to specific virtual machines.
The authors go on to say how all the devices, from the physical RAM itself, to hard disks, to network cards, to the processor cores, get partitioned such that each virtual machine only sees and uses hardware dedicated to it. And by doing this, the authors claim that this reduces the virtualization tax - the slowdown in performance caused by the overhead of the hypervisor itself and the additional traps (or "VMEXIT events") induced by virtualization and other overhead related to sharing hardware (for example, having two virtual machine hard disk images on the same physical hard disk).
Now, I do not disagree with much of that logic. The hypervisor ideally should be a thin layer of code and the hypervisor should induce as few hardware traps as possible. But can one truly eliminate such a layer and still have virtual machines that can be started, stopped, and live migrated to another host?
NoHype replaces the hypervisor with what they call a "Core Manager" which is a small piece of software which sets up the virtualization state, use the nested page table capability of VT-enabled processors to create a physical memory mapping and device mapping, and then starts the virtual machine running.
Ok, that all sounds good on paper, and the authors go on to make claims that with a little bit of extra hardware, most of which is available today, this would now provide totally secure virtual machines and be a "commercially viable solution". The end. That's it, that is the paper in a nutshell, here is the link again if you do not believe me:
http://www.princeton.edu/~szefer/publications/isca10.pdf
My obvious issue with the NoHype paper: where is the data and where are the implementation details to back up any of the claims?!?!?
If this had been some security workshop and the authors wished to educate paranoid IT people about best practices to apply to virtual machines, I would have no problem with this paper. Certainly, if you dedicate specific hardware to specific virtual machines you may cut down on overhead. Hypervisors such as VMware Workstation already today allow you to do such things, to dedicate a specific physical hard disk to a specific virtual machine, to limit the VM's physical memory such as to not over commit memory, etc. As a set of security practices to help reduce risk the paper would have worked somewhere else.
But this was ISCA and they made some pretty bold claims. This was a computer architecture conference full of engineers like me who travelled thousands of miles and paid 500 Euros to attend a conference expecting to see solutions to problems and see data presented for bold claims. Every single other paper, the presenter gave an introduction to show some problem, he make some claim, he presented data to support the claim, conclusion. The end.
Do you see my problems with this paper? These were post-graduate Electrical Engineering students from Princeton University presenting a paper containing ZERO DATA. No performance numbers. No cost analysis. No security threat modeling. Just bold claims not backed up by any data.
Here is my take on this concept of eliminating the hypervisor. Cloud computing providers today provide two types of "instances" of cloud machines:
- those running in virtualization, such as Amazon's EC2 cloud (http://aws.amazon.com/ec2/), and,
- those running on bare metal hardware, such as newservers.com, where each cloud machine is dedicated bare-metal hardware, priced a little higher than Amazon's rates.
What the NoHype paper proposes is a third type of cloud product, a hybrid where the instance is almost bare metal but running on a host machine that is really hosting other virtual machines as well. For example, you could use a 128-core machine with 256 gigabytes of RAM and 32 hard disk drive and a virtualization-aware network card to host 32 quad-core virtual machine instances of 8 gigabytes each without any oversubscription on memory or hardware. Sounds like an absurdly expensive machine, no? Yet the 128-core and 256GB examples come straight out of their paper.
How do they do this partitioning without a hypervisor? Lots of people wanted to know. As soon as the NoHype presentation concluded and the Q&A session started, many hands in the audience went up, including my own. Several people from VMware who were at the NoHype presentation made the observation that the Core Manager was in fact a hypervisor. They also objected to the claim that all hypervisors have the same security vulnerabilities as OSes, since VMware's hypervisor is not derived from an OS but rather is custom code. When it was my turn to ask questions, I had the same objection about the Core Manager, but the presenters stuck to their guns claiming that it was not a hypervisor.
Both the live presentation and the paper even go so far as to devote space to pointing out how clever the "NoHype" name is. "NoHype" is a double entendre, to indicate the complete elimination of the hypervisor from their solution, and that their paper contains no hype. I say they fall flat on both counts. First, because if you make unfounded claims I believe that qualifies as hype! Second, I do not for an instant believe they have eliminated the hypervisor. What they call the Core Manager is memory-resident code which has to be present for the lifetime of the virtual machine to be able to start the virtual machine in the first place, stop the virtual machine in order to shut it down, or pause the virtual machine in order to migrate it to another host. Those are classic functions of a Virtual Machine Manager (VMM), better known as... a hypervisor.
After ISCA I emailed the authors of NoHype to express some concerns and ask questions. I did receive two replies indicating that the NoHype software has not actually been implemented yet, that they had no hard performance data to quantify the "virtualization tax" numbers, and that they had no cost analysis to put a dollar amount on the implementation costs of NoHype. In the email the authors reframed the Core Manager as a "bootloader". However, I do not believe that the requirements of a bootloader are met, due to the fact that the Core Manager stays memory resident and stays active thus being open to exploits and security attacks. Whereas a true bootloader does its job then is removed from memory, a big distinction.
I asked about their claim about being "commercially viable", commercial viable for who? To the bare metal provider such as newservers.com who I might think could build several inexpensive systems for the price of one mondo 128-core monster? Or relative to someone like Amazon, who like other cloud providers would need to spend additional money to implement the NoHype policies and thus would have to raise their prices? Where on that spectrum does the NoHype approach end up in price? Answer is not known yet because they cannot provide such data, but they can definitively claim in writing to be "commercially viable". Huh?
There is of subtle detail easily overlooked, and that is the hardware requirement of needing to use VT-enabled processor. VMware, VirtualBox, Xen, and other hypervisors do support running on older non-VT hardware such as the Pentium 4. Such a VT requirement immediately renders the NoHype approach unsuitable for deployment on a vast number of existing machines, such as the Pentium 4 machines which I have found to be the basis of newserver.com's cloud machines, or on the most recent Intel Atom based servers offering up to 512 cores in a $139000 box:
It would seem that two ways to achieve the "commercially viable" goal would be to minimize the cost of electricity to run the servers, and/or to reduce the initial purchase price of the hardware. Atom based system reduce power consumption and are inexpensive. Pentium 4 based system while not overly power efficient are cheap cheap cheap these days. So by requiring more expensive VT-enabled hardware it seems the NoHype approach already cripples its commercial viability in two major ways.
I am not comfortable putting blind faith into the security of the hardware, which we know from the AMD Phenom fiasco is not something you want to do. In the NoHype paper, the authors concede this point, by stating:
"We acknowledge that the hardware and firmware may not be completely free of bugs, however, we feel that the extensive testing and relatively non-malleable nature of the hardware and firmware configurations (when compared to software) makes it more difficult to attack."
Now the claim is that it merely reduces the security threats. By how much? Relative to what? Where is the data? Are they comparing against Xen, against VMware ESX, what is the reference case? For example, if I read about the Lynuxworks hypervisor (http://www.lynuxworks.com/virtualization/hypervisor.php) which sounds pretty impressive in itself, where is the data to show that the NoHype approach is any more secure. I'm a naive consumer wishing to set up a datacenter. I see one claim from Lynuxworks that says trust their hypervisor. I've got this other claims from NoHype saying trust the hardware. Because if NoHype is not more secure, why would I spent the money on the additional hardware?
If we can accept the fact that neither hardware nor software can ever be bug free then the risks and costs of each need to be quantified. A problem I have with the NoHype approach is that it requires much greater faith in hardware, requiring the use of specific processors and additional specialized hardware.
What is thus missing from the NoHype paper is compelling analysis and data to convince me that the hardware investment is worth it. Because a simple alternative to investigate would be to take an existing hypervisor, say an open source product such as Xen or VirtualBox that can easily be modified and those patches shared with the rest of the community, and rip out code not needed for the NoHype approach. How many lines of code (relating to over-committing of resources and such) would that eliminate in itself? That by itself would have made for an excellent paper and set a bar, some reference point, against which the additional hardware costs and benefits could be evaluated against. I want to know how much security risk does sharing a core between multiple virtual machines introduce. A valid question, no?
Another question not answered in either the NoHype paper of the subsequent email response is the issue of CPUID masking for live migration. VMware and others have put out considerable literature concerning the problem of migrating virtual machines across different types of host hardware where CPU capabilities might not be identical on the two host machines. A virtual machine should not be able to detect the migration or that the host hardware had suddenly changed out from under it as this could lead to crashes (especially when the capabilities have been reduced, such as if migrating from a newer Core 2 processor to an older model Core 2) or undefined behaviour. What happens if the clock speeds of the two systems are not the same? What if the cache sizes are not the same? What if the underlying hardware is not the same. If you read the literature, existing hypervisors jumps through all sorts of hoops in an attempt to make live migration work, and this relies on the hypervisor actively trapping on certain instruction such as CPUID and on I/O accesses to emulate a consistent set of hardware. A large datacenter cannot possibly maintain hundreds or thousands of identical machines for all time. Machines die, new machines containing newer (different) hardware replace them, and virtual machines must not detect this change. The NoHype paper claims that the Core Manager would not need to do any of this, yet gives no concrete details on how live migration would work.
Finally, since conference papers are generally submitted many months in advance, I would have expected some additional data to have been presented at the live presentation. As in "here is what we wrote in the paper six months ago, and now here is data we've collected in the six months since". They showed nothing new. Nada. Zip. So I have to say, the NoHype proposal disappointed me and I am stumped to understand how this paper was accepted into this year's ISCA when according to the conference proceedings book over 200 other papers which were submitted were rejected. Is this the new trend now to publish research that contains no data?
For all we know the NoHype approach is safer, cheaper, and faster than any existing virtual machine implementation out there. But the authors fail to give any shred of hard evidence to back up their claims, and ask the reader to accept certain assumptions on blind faith. I'm sorry, but I cannot accept that.
Alternatives to using Hardware Virtualization in the Cloud (or, How iPad Changes EVERYTHING)
I will bring up one final glaring omission of the NoHype paper: the lack of any kind of discussion related to emulation based virtual machine implementations. Is it just assumed that any virtual machine implementations in the future will rely on VT-enabled hardware? I for one, for reasons relating both to my Intel Atom example and my ongoing work in emulation, do not by any means blindly assume that. Let me give you a great reason why.
Back in Part 7 (my "One Night In Paris" posting from October 2007) I described my summer 2007 vacation in Europe and the frustration of not being able to transfer a Windows sessions between two laptops as one of them was running out of battery power. I suggested that the next "killer app" would be for a virtual machine hosting service which would permit me to have my home computer environment sitting in a server cloud somewhere, which I could access from anywhere in the world from any computer at any time. My own personal always-on computer in the cloud.
Oh how naive I was (and boy do I wish I had loaded up on Amazon stock back then). Because little did I realize that by 2008, when VMware was merely blowing smoke about their VDI product, Amazon and others were already setting up exactly such cloud infrastructures to offer what today we all know as "cloud computing" services. Doh!
This time around, when I was at ISCA a few weeks ago, I needed to only bring a small netbook to serve as my terminal into the cloud. And it worked, well, for as long as I had a wi-fi connection at the conference or anywhere else in St. Malo. The Amazon instance which I used cost about 8 cents per hour, which is almost comparable to the electricity costs of setting up a server at home to leave it running the whole time I was in Europe. An added bonus is that my cloud machine behaved as if it was back home here in the U.S. instead of popping up with a French version of MSN and Google home pages. Pretty neat!
Oh how close to my killer app from three years ago. But what exists today is still short one cool feature: to be able to seamlessly migrate a virtual machine to the cloud and back, which today would still be greatly impaired by slow Internet and wi-fi connections. But assume for a second a fast connection, when I have lots of battery power I pull down my virtual machine instance to my laptop, use it locally for a few hours possibly offline from the Internet, then before the battery dies I connect to the Internet and sync back up to the cloud instance and then access it from another machine. That is my ideal cloud computing scenario.
In fact, the recent release of Apple iPad makes such a scenario even more compelling. For that would permit a small thin device with mostly always-on Internet connectivity such as the iPad (or the rumored Dell ARM-based netbook) to provide access to cloud instances while still having the juice and horsepower to run applications locally if so desired.
Only one problem. How would one go about implementing that last step given that the iPad is not based on an x86 processor? Nor is the rumored ARM-based Dell netbook and similar such low-cost ARM tablet devices supposedly coming to market soon, which will all be able to run an ARM based Linux but which will be unable to natively run Windows. The best solution today is to run an Intel based laptop or an Atom based netbook, but that does not address the iPad or the coming wave of ARM devices. Are these devices destined to just be dumb terminals into the cloud? In which case, yes, there is a Remote Desktop app for that: http://itunes.apple.com/us/app/remote-desktop-lite-rdp/id288362576
In various postings and papers in 2008 I compared QEMU and Bochs and Hyper-V to make a point about just how much potential improvement there was in all these various forms of emulation and virtualization. My argument then (as it still is today) is that through a combination of hardware marketing propaganda and a general lack of software emulation experience, engineers have falsely arrived at the belief that native execution of code (and the accompanying hardware virtualization features that "requires") are the best way to implement virtual machines. However, as Keith Adams at VMware showed in 2006, there is a virtualization tax regardless of the method used, whether emulation or VT-based virtualization.
Take Bochs for example. It is a nice clean purely C++ based implementation of a full system PC simulator capable of emulating MS-DOS, Windows, Linux, and today even 64-bit Windows 7 and 64-bit Linux. Yet when I started using Bochs a few years ago it was painfully slow (on the order of 100x slower than native speed) and people naively wrote that slowness off. "Interpreters are slow". Until I dove in, nobody really took seriously that maybe the interpretation was slow because it was implemented poorly? As you know, Bochs 2.4.5 today is almost 4 times faster. And as I keep blogging and writing and finding new optimization tricks, I am convinced that there is still at least a doubling of performance potential there to be had. A 200 MIPS purely interpreter x86 emulator? Sure, but I will also admit that would fail the "commercial viability" test if it provided cloud services running 20 times slower than expected.
Bochs is arguably the most accurate virtual machine product out there, as verified by several research papers which looked into correctness and security issues in virtual machines. So speed aside, that is a big benefit. Let's put Bochs on the back burner for now and I'll come back to it in a future posting.
What about Microsoft's Virtual PC? In the 1990's a small company called Connectix made a PC emulation product for PowerPC-based Macintosh computers called Virtual PC for Mac. This product out of necessity was based on dynamic recompilation "jit" technology, since PowerPC processors do not directly execute Windows code targeted at Intel x86 processors. Microsoft acquired Connectix in 2003, rebranded Virtual PC as their own product, and released a Virtual PC 7 upgrade for the Apple Mac G4 and Mac G5. So although not targeting ARM, PowerPC and ARM are fairly similar instruction sets, so Microsoft's Virtual PC would seem to be a contender to some day provide Windows emulation on ARM device, no?
Ah, but then they ported Virtual PC to Windows, reworked it into a server virtualization product called Virtual Server, discontinued the Macintosh version entirely in late 2005, then morphed the product again into Hyper-V which required the VT hardware virtualization support. Even the Windows Virtual PC "XP mode" in Windows 7 required hardware virtualization when Virtual PC launched. Dead end.
Unfortunately, the mainstream virtualization community (along with some nudging from the hardware community) preaches the religion of hypervisors and hardware virtualization - or as I think of it, the blind faith that hardware knows best. In addition to my ranting from today, I showed in 2008 in Part 19 how problematic VMware Workstation 6 was to use, and in Part 26 how Hyper-V could be the poster child of how not to write a hypervisor. Hyper-V fails my cloud-on-iPad test by virtue not only of requiring an x86 processor but of requiring one with the VT hardware virtualization support, which thus fails on Intel Atom based netbooks. The NoHype approach if it has any merit fails for the same reasons. VirtualBox, VMware, Parallels, and now Virtual PC and Virtual Windows, they too all fail the test being x86-only hosted products these days, and thus they fail on any ARM device.
Interestingly the VT brainwashing might have continued had the world economy not tanked in 2008. People slowed down their purchases of latest and greatest hardware, and many gravitated to cheaper Atom-based netbooks and nettop machines. Atom processors don't support the VT hardware virtualization feature, just as older Pentium 4 and Xeon machines do not either, so those users of Windows 7 were not able to use the "XP Mode". So what did Microsoft do when customers complained about not being able to access? Earlier this year, they simply dropped the hardware virtualization requirement!
In other words, Microsoft tells the world that Virtual PC in Windows 7 absolutely requires requires requires hardware virtualization support. People push back about needing to buy new hardware. And so one day in March 2010 the very same Microsoft says of the very same product, oops, no, you did not actually need the hardware virtualization feature, exactly what I have been ranting about since 2007. Hardware virtualization is more a marketing "feature" than anything of necessity.
Oh, but wait! Hardware virtualization is a security feature, it's more secure than using dynamic recompilation, r-i-g-h-t? Well, that argument falls flat on its face because more than 6 months before Microsoft dropped the hardware virtualization requirement, people had discovered a glaring security hole in that very same Windows Virtual PC product in Windows 7:
http://news.cnet.com/8301-27080_3-20000594-245.html
They left the hypervisor address space wide open for exploit, ooops! So much for all the security of having hardware memory protection when some bozo leaves the front door wide open.
Look. ALL virtualization approaches, whether interpretation based, dynamic compilation based, or hardware virtualization based, are vulnerable to security exploits if the people developing the virtualization product are sloppy. As the AMD Phenom launch back in 2007 showed, the virtualization hardware itself can introduce bugs and security holes and shouldn't be trusted, making virtualization a software problem to solve. Why are people still trudging along in the pursuit of direct execution using hardware virtualization? Don't ask me, because as far as I am concerned it is a bad idea. Especially in the age of cheap ARM devices, portability and the need to some day perform live migration between x86 and ARM hosts will be vital to truly have the kind of fluid cloud computing infrastructure which I envisioned back in 2007.
In Virtual PC's case, turning off the VT requirement simply meant reverting to an older form of virtualization used in the past by Virtual PC and VMware called "ring compression". It is not a fully "jitted" approach and does still mainly rely on direct execution of Ring 3 user mode x86 code, which thus still fails the cloud-on-iPad test.
You might rightly ask, what other alternative is left?!?!?
Why QEMU Matters
Now consider QEMU (http://wiki.qemu.org/download/qemu-doc.html), described as a "FAST!" processor emulator, which is partly true. As with Bochs, it is capable of emulating a PC running MS-DOS, Windows, or Linux, and also can emulate various other non-Intel processors such as 68040 and PowerPC. QEMU uses the technology of dynamic recompilation (a.k.a. "jitting") to translate code on-the-fly to the local host machine's instruction set, in the belief that this is faster than interpretation. QEMU runs on not just x86 hosts, but also on PowerPC hosts, MIPS hosts, and yes, ARM hosts.
But as far as performance, in past postings I dismissed QEMU as a rather slow alternative to Bochs, running roughly 6 times slower than native x86 code on the same host hardware. Once Bochs was tuned and made much faster back in 2008, QEMU at the time (version 0.9) was generally about twice as fast as Bochs and in some scenarios no faster than Bochs. So does sometimes being maybe twice as fast really qualify QEMU to be called "FAST!" in capital letters? And is QEMU really running as fast as it can?
The good news is, no it is not! The past few weeks I have been building the latest QEMU 0.12.5 sources from http://www.qemu.com/qemu.git/ and testing it out on various machines to see what the performance is like - from Intel Atom netbooks to quad-core Core i5 machines to Apple Mac G5 and Apple Mac Mini G4 machines. QEMU runs much better on those systems than the 0.9 version I tested two years ago, but several obvious jit code quality issues still remain (not unlike similar Bochs performance issues discussed two years ago - flow control, arithmetic flags handling, and memory sandboxing). Therefore, there is significant room for speed improvement.
To close out today's posting, I will summarize with this:
With some of the optimization tricks borrowed from the Bochs interpreter, QEMU could hold the key to providing a non-VT alternative to virtualization on mainstream PCs. It is also the key to providing x86 emulation to ARM devices such as iPad and opening up the world of cloud computing to a much broader spectrum of computing devices. QEMU already supports the emulation of both 32-bit and 64-bit x86 guest code. It already supports the emulation of multi-core guest virtual machines. QEMU's device model is already used as the basis of device models in VT-based virtualization products such as Xen. And just like Bochs, once can build QEMU on Windows, on Mac OS X, and on Linux based hosts.
What it all comes down to are two critical issues:
- optimizing the performance of QEMU's jitted code on x86 and RISC hosts, and,
- verifying the correctness of QEMU's x86 behaviour using something like Bochs as the golden x86 reference.
QEMU's x86 correctness leaves a lot of be desired, and that was one of my criticisms about it two years ago. It simply did not correct results as Bochs did, and this unfortunately is one of the incentives for virtualization developers to give up on the emulation based approach of QEMU and let hardware do the heavy lifting by means of direction execution and hardware virtualization. To me, that is just the sign of lazy programmers. Both of these issues are perfectly solvable and achievable goals. The end result - the hosting and seamless fluid live migration of virtual machines between any arbitrary set of Intel, AMD, PowerPC, MIPS, and ARM devices - seems to me a beneficial payoff well worth a little bit of engineering effort.
I will continue this QEMU discussion later this month after a quick little look back at the PowerPC in my next posting.