NO EXECUTE! A weekly look at personal computer technology issues.
(c) 2007 by Darek Mihocka, founder, Emulators.com.
October 22 2007
The Software TLB Revisited
mov edi,ebp
shr ebp,12
xor edi,[pagetbl+ebp*4]
; js ReadHW1
mov bx,word ptr [edi-1]
unsigned short ReadGuestWord(unsigned long addr)
{
return (unsigned short *)(pb[(addr ^ pagetbl[addr >> 12]) - 1]);
}
To refresh your memory, this code maps a 32-bit guest effective address in the EBP register to a host address in EDI, using a 4K page granularity for the mapping. The 32-bit address is split into two components, the 12-bit lower bits which are the byte offset into the page, and the upper 20 bits which are the page index. Therefore 2^20 = 1048576 unique pages of guest addresses exist in a typical 32-bit 4-gigabyte address space.
While this code does fundamentally work, it has some performance issues and some subtle bugs. On the performance issue, notice that this code is very serial. Each instruction depends on the output of the previous instruction. This is very serialized data dependency. On a modern CPU the data dependency between two integer instructions (such as the MOV and SHR) means that at best those instructions complete in separate clock cycles. On some CPUs such a dependency may even cause a two clock cycle spacing. Address generation dependencies, such as the dependency between the SHR and XOR, and again the XOR and MOV instructions, can typically cost three clock cycles or more. Therefore this clock sequence will take about 8 clock cycles to execute.
Worse, our evil friend the original Intel Pentium 4 lacked what is called a "barrel shifter" circuit, which is necessary to quickly perform shift operations such as the right-shift instruction SHR and the left-shift scaling operation EBP*4. On the original 1500 MHz Pentium 4 I measured this extra shift latency at about six clock cycles in worst cases. On such a Pentium 4 this code takes too many cycles than I care for.
Looking at correctness, this code has some subtle edge case bugs. For example, what happens if the address being mapped happens to be the last byte on a 4K page and the data access is a 16-bit load as shown? This is a spanning access which actually reference two entirely different pages of memory, both in the guest address space and in the host address space. For this code to function, it means that guest addresses must map linearly to host addresses. Otherwise the code will fail on what are called "spanned accesses" across two pages. I was aware of this issue and it was acceptable for Gemulator 2000 and SoftMac 2000, as those emulators did allocate the guest memory block in one contiguous block and also did not emulate the 68030 and 68040 MMU functionality. This is not an acceptable compromise though if emulating PowerPC or x86 architectures which do rely on a page granularity of mapping.
This is also really not acceptable on the grounds that it gets progressively more difficult to allocate a contiguous (i.e. unbroken) chunk of memory on Windows. I ran into problems trying to allocate even 1024 megabytes of Macintosh guest RAM, as Windows memory tends to get very fragmented. One particular release of DirectX had some very fragmented DirectDraw DLLs which made it impossible to actually allocate more than about 512 megabytes. So one important issue I want resolved is the ability to support fragmented host memory while supporting page granularity mapping of guest addresses.
Another bug I ran into on 64-bit Windows, which raised the available user-mode address space for 32-bit Windows applications from 2 gigabytes to 4 gigabytes. In all previous 32-bit Windows release, user mode memory ended at address 0x7FFFFFFF. In 64-bit Windows it goes right up to 0xFFFFFFFF. I already hinted last week that for Gemulator 2008 and SoftMac 2008 I uncommented all of the conditional jump instructions so as to reduce page faults. But my conditional jump relies on the valid host address falling into the range of addresses of 0 through 0x7FFFFFFFF. If 64-bit Windows chooses to give the emulator a block of memory in the upper 2 gigabytes of address space, my code suddenly always ends up in the hardware emulation handler. Oops! The bug to fix therefore is to not assume anything about the size or layout of host memory.
A very subtle bug is an alignment issue. The 68000, and even the x86 in the right conditions, does not allow for unaligned memory accesses. What that means is that if the address being accessed is odd, and the memory access spans more than one byte, the 68000 actually throws an exception. My code in Gemulator and SoftMac did not support this consistently. The alignment check was made in the exception handler itself but not in the fast memory access code above. Therefore it is possible to erroneously permit a 68000 memory access to succeed where it would have throws an exception on a real Atari ST. Therefore byte alignment and page-spanning must strictly be checked for an enforced.
A final performance issue has to do with that constant "12". Why did I choose twelve? I chose 12 because that is the number of bits needed to represent a 4K page. 2^12 = 4096 = 4K. But in an emulator, nothing is written in stone that the emulation itself must perform its mapping at that same 4K granularity. The constant that I actually used in Gemulator 2000 and SoftMac 2000 is 16, mapping guest memory to host memory at 2^16 = 64-kilobyte granularity. It turns out that on both the Apple Macintosh and the Atari ST, the type of memory does not change at less than 64-kilobyte increments, and usually does so at 1-megabyte increments. RAM size is always a multiple of 256K. ROM size is always a multiple of 64K. Since the emulators were not yet supporting the guest MMU, it was sufficient to use 64K mapping granularity. This shrunk the size of the mapping table from 2^20 = 1048576 entries to just 2^16 = 65536 entries, a significant reduction in memory overhead of the emulator as well as giving a reduction in host data cache misses at run time. Ideally we want the software TLB to be even smaller, so that it does not pollute a significant portion of the host's data cache.
One way to reduce the size of the mapping table is to just have less entries! Instead of using all of the upper bits of the guest address to calculate a table index, real CPU hardware, such as that used in L1 caches and Translation Lookaside Buffers, only uses a subset of those bits. What you now have is a hash table, where multiple guest addresses can hash to the same entry in the table. This means that a smaller mapping table now needs to contain two entries - the magic XOR value as before, and a new value which is the address of the guest page being mapped.
Going back to the original C code, a modified scheme that uses such a hash table with only 65536 entries may look something like this:
unsigned short ReadGuestWordHashed(unsigned long addr)
{
unsigned long addr_page = addr & 0xFFFFF000;
unsigned long table_index = (addr >> 12) & 0xFFF;
if (pagetbl[table_index].addr_page == addr_page)
{
return (unsigned short *)(pb[(addr ^ pagetbl[table_index].xor_value) - 1]);
}
return ReadGuestWordHandler(addr);
}
This address check also handles the elimination of trap-and-emulate faults because guest page addresses which would produce such a fault would never be added to this hash table. This in turn always forced the slow path, the ReadGuestWordHandler function to be called.
However, this code does not handle the misaligned data access issue, nor does it handle the permissions issue where the page might be readable but not writeable, nor does it handle the page-spanning issue. Oy!
One simple way to handle this is to have another data field in each hash table which contains permission bits, such as whether the page is readable or writeable. This would bloat the size of the table. An alternate technique is to realize that the page offset bits do not need to checked for a match. The 'addr_page' value in hash table entry is rounded down to a 4K value, meaning that the lowest 12 bits of that value are zeroes. Similarly, the code is explicitly masking out the lowest 12 bits of the address being passed in. Therefore instead of an exact match, it is only sufficient to check for a match of the upper address bits.
XOR To The Rescue (Again!)
Let me show you a very basic computer science trick: when you XOR two values together, A XOR B = C, the value C contains a bit vector of bits that are different in values A and B. That is, for each bit position in A and B, that same bit position in C will be zero if the bits in A and B matched, and will be one if A and B differed. To better visualize this, let us look at a numeric example, the integers 3 and 7, which in binary are expressed as 0011 and 0111 respectively. 3 XOR 7 is 4, or 0100 in binary. Why is that? Let's look at each bit in detail:
| A = 3 | 0 | 0 | 1 | 1 |
| B = 7 | 0 | 1 | 1 | 1 |
| C = A XOR B = 4 | 0 | 1 | 0 | 0 |
As you can see, the values 3 and 7 only differ in one bit position when represented in binary. The XOR-ed value C is a vector of all those bits which differ. Therefore, to test for equality of two numbers A and B, the equality (A == B) can be rewritten in the form ((A XOR B) == 0). Or, to verify that only specific bits are equal, for example to make sure that the lowest two bits of two values match, one would use the expressions (((A XOR B) & 3) == 0).
So, going back to our address mapping problem, if the bottom 12 bits of the address comparison are known to be zero, we can avoid comparing the by modifying the "if" statement:
unsigned short ReadGuestWordHashed2(unsigned long addr)
{
unsigned long addr_page = addr & 0xFFFFF000;
unsigned long table_index = (addr >> 12) & 0xFFF;
if (((pagetbl[table_index].addr_page ^ addr_page) & 0xFFFFF000) == 0)
{
return (unsigned short *)(pb[(addr ^ pagetbl[table_index].xor_value) - 1]);
}
return ReadGuestWordHandler(addr);
}
What this now gives us is the ability to store 12 bits worth of flags in the hash table without bloating the memory size of the hash table. We can take this further, when we realize that the bits being used to calculate the table_index value are also guaranteed to match, further reducing the number of bits that need to be compared, and saving one masking operation:
unsigned short ReadGuestWordHashed3(unsigned long addr)
{
unsigned long table_index = (addr >> 12) & 0xFFF;
if (((pagetbl[table_index].addr_page ^ addr) & 0xFF000000) == 0)
{
return (unsigned short *)(pb[(addr ^ pagetbl[table_index].xor_value) - 1]);
}
return ReadGuestWordHandler(addr);
}
We can handle the misalignment issue by realizing that the addr_page value in the hash table always has zeroes in the lowest bits. If the address being in is misaligned to an odd address, the XOR result will also produce an odd value. Therefore it is as simple as changing one digit of the constant to handle misalignment:
unsigned short ReadGuestWordHashed4(unsigned long addr)
{
unsigned long table_index = (addr >> 12) & 0xFFF;
if (((pagetbl[table_index].addr_page ^ addr) & 0xFF000001) == 0)
{
return (unsigned short *)(pb[(addr ^ pagetbl[table_index].xor_value) - 1]);
}
return ReadGuestWordHandler(addr);
}
Similarly, by artificially setting a bit in the hash table's addr_page field (say, the bit corresponding to mask 0x00000080) to indicate that a page is read-only, and checking for that bit in the "if" statement, one can now use a similar line of code if this had been a write operation. The follow line of code will fail the comparison if the page is not writable:
if (((pagetbl[table_index].addr_page ^ addr_page) & 0xFF000081) == 0)
You can see the pattern now. The "if" statement is not only checking whether the hashed page address matches the access page address, it is also checking the alignment of the access, and checking optional flags, all with no additional overhead. There is only one issue left now, which is to detect that the memory access is spanning a guest page. For the August 2007 beta releases of Gemulator 2008 and SoftMac 2008, I did this by applying a "fudge factor" to the calculation of the table index.
The purpose of the fudge is to calculate the table index not of the starting byte of the guest memory access, but rather of the ending byte of the guest memory access. Only if the entire guest memory access fits within one page will the table index be correct. If the access spans a page, the table index that will be calculated will be off by one and will make the "if" statement use the wrong hash table entry. The XOR and the comparison will then fail, making the code fall through into the hardware handler.
unsigned short ReadGuestWordHashed5(unsigned long addr)
{
unsigned long table_index = ((addr + fudge) >> 12) & 0xFFF;
if (((pagetbl[table_index].addr_page ^ addr) & 0xFF001001) == 0)
{
return (unsigned short *)(pb[(addr ^ pagetbl[table_index].xor_value) - 1]);
}
return ReadGuestWordHandler(addr);
}
There is a very subtle "gotcha" here, in that this requires checking the 13th bit of the XOR result. If in fact the access spans a guest page and the table index is off by one, this will cause a mismatch in the 13th bit (and possibly the 14th through 24th bits as well). This "off by one" mismatch therefore needs to be checked for.
Compile the above code in a C compiler and it will not be pretty. What I did in the 68040 engine of Gemulator 2008 and SoftMac 2008 therefore was change the mapping granularity from 4096 bytes to 256 bytes. I also shortened the hash table to contain only 256 entries. This means that the page offset if in the lowest 8 bits of the guest address, while the hash table index is extracted from the next higher 8 bits. It would be equivalent as if the C code was written like this:
unsigned short ReadGuestWordHashedWithFudge(unsigned long addr)
{
unsigned long table_index = ((addr + fudge) >> 8) & 0x0FF;
if (((pagetbl[table_index].addr_page ^ addr) & 0xFF000101) == 0)
{
return (unsigned short *)(pb[(addr ^ pagetbl[table_index].xor_value) - 1]);
}
return ReadGuestWordHandler(addr);
This still has a performance issue, in that by putting in the "+ fudge" into the table_index calculation, it delays the hash table lookup by one clock cycle. A slightly more optimal version of this code is to do the table_index calculation as quickly as possible, and use the roughly 3-clock-cycle address generation window to apply the fudge to the address. Remember, most CPUs are faster at handling data dependencies on arithmetic calculations than they are on effective address generation. So a final version of this code, show here for a 32-bit guest memory read would look like this:
unsigned short ReadGuestLong(unsigned long addr)
{
unsigned long table_index = (addr >> 8) & 0x0FF;
if (((pagetbl[table_index].addr_page ^ (addr + /* fudge */ 2)) & 0xFF000101) == 0)
{
return (unsigned short *)(pb[(addr ^ pagetbl[table_index].xor_value) - 1]);
}
return ReadGuestWordHandler(addr);
Notice that the "fudge factor" is 2, not 3 as you might think. It is not necessary to add three, because the alignment check catches that case, i.e. when the incoming address in addr is odd. So we only need to add 2 to catch the case of
This is what the assembly language code looks like that I am preparing for the upcoming Gemulator and SoftMac 2008 Beta 2 releases, where the ECX register contains the incoming guest address, EAX is used as a temporary to calculate the table index, EDX is used as a temporary to reference the host memory, and the loaded value is returned in EAX:
movzx eax,ch ; extract bits 15..8 to get table index
mov edx,ecx
add edx,2 ; apply fudge factor for dword spanning check
xor edx,pagetbl+eax*8
test edx,0FFFF0101h ; check for address mismatch, misalignment, and/or spanning access
mov edx,pagetbl+eax*8+4 ; map and adjust for endianness
jne ReadHWLong ; branch to slow path if any of those mismatches detected
xor edx,ecx ; map the guest address to host address
movzx eax,dword ptr [edx-3]
This code follows Microsoft Visual C/C++ register calling convention, so this code is in fact a direct assembly language equivalent, and C-linkable version, of the preceding C code.
Unlike my previous attempts at a software-based TLB, which required lookup tables of 65536 to 1048576 entries, this hash table only requires 256*4*2 = 2048 bytes of host memory. It imposes a minimal footprint on the host's L1 data cache and L2 cache. The code also contains some amount of instruction-level parallelism, so even though it is a fatter code sequence that my previous attempts, it executes in about the same number of clock cycles and performs much better checks and tests than the previous code did.
The constant used by the TEST instruction (or the C "if" statement) contains 7 bits that can be used as flags, the bits that correspond to the bit mask 0x0000FE00 of the address. These 7 bits can thus be used to flag entries which for example, are read-only, which are supervisor-mode-only, which can only be accessed in certain modes of execution, etc. It is up to the actual implementation of a virtual machine to decide how to use these 7 bits, but just keep in mind that these represent up to 7 additional tests that you can perform for free during the guest-to-host address translation.
This sweet and elegant 9-instruction code sequence replaces the need to use or even have a hardware MMU on the host. It eliminates the ugly VMM exception handler that plagues so many other virtual machines. It places no requirements on the amount of host physical memory available, since it at most maps 256*256 = 64 kilobytes of guest address space into the host at any one time. The implementation of the virtual machine is free to choose whether to actually have a large block of memory containing the guest RAM at all times, or whether to load in 256 bytes at a time as needed.
But Is It Fast?
My greatest fear when I was making these changes to the Gemulator and SoftMac code was that this would ultimately end up being slow. Thankfully, I was pleasantly proven wrong. This code actually reduces the "unsafe code tax", since it no longer generates any host memory access exceptions, it eliminates thousands of lines of C code in the virtual machine which was devoted to decoding the faulting x86 instruction and emulating the memory access, and it greatly reduces the memory footprint of the virtual machine's execution state.
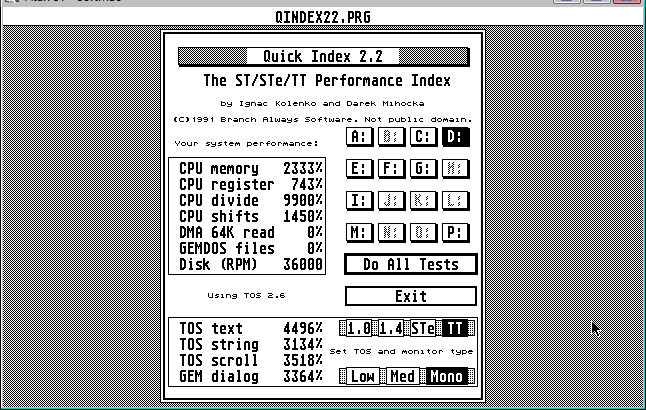
I compared a bunch of different Atari ST and Mac test programs which I have used for many years to both test the accuracy of my emulators and to benchmark the performance. Two particular Atari ST benchmarks which I have used for a long time (which I was referencing even in the 1990's on our Benchmarks page) are Quick Index and GEM Bench. My old business partner Ignac and I wrote Quick Index in college when we were marketing the Quick ST software acceleration product for the Atari ST. I was intended to compare various acceleration products, hardware and software, and so it performs four CPU-bound tests on memory and arithmetic operations (for testing CPU acceleration boards), and four more graphics tests which exercise text output, string output, screen scrolling, and dialog box rendering for testing Quick ST. I have literally not modified the source code to Quick Index in over 16 years and I have used it as one of my basic benchmarking tools for studying code optimization tricks.
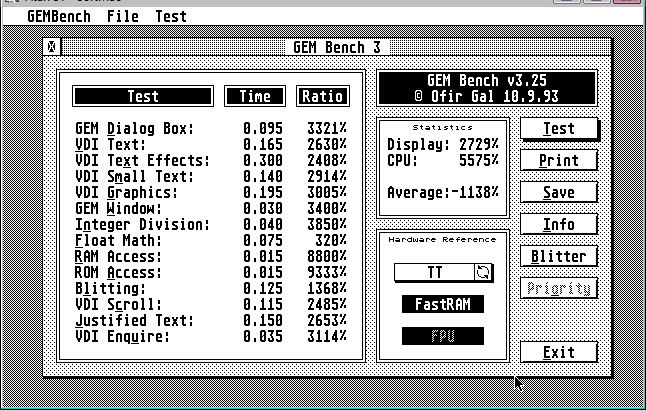
GEM Bench was written independently in the U.K. and performs slightly more detailed sets of the kind of tests that Quick Index performs. I use the two benchmark programs as sanity checks against each other.
What I present here first are two screen shots of a build of Gemulator 2000 running on a 2.6 GHz class Pentium 4 Prescott microprocessor and Windows Vista. This is a private build of Gemulator 2000 which was never released (and I erroneously built as SoftMac, ha). It contains additional performance tweaks for Pentium 4 and Core 2 and fixes for Windows Vista to essentially make this the fastest build of Gemulator that used the older 65336-entry address mapping and trap-and-emulate methodology.
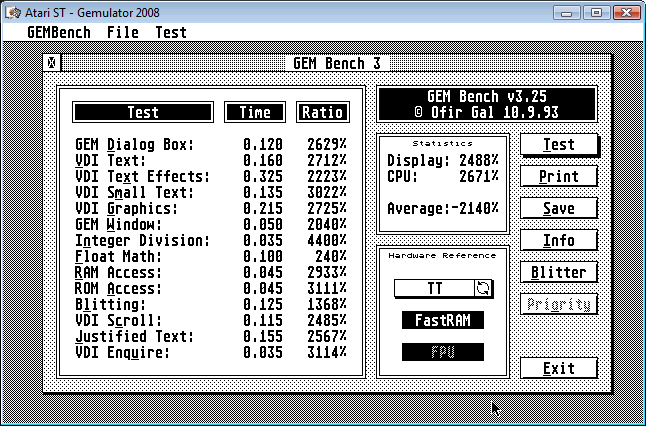
Now I present screen shots of the exact same tests, running on the exact same computer just minutes later, using a build of Gemulator 2008 Beta 2 that contains the new XOR-based memory mapping code. What do you notice?
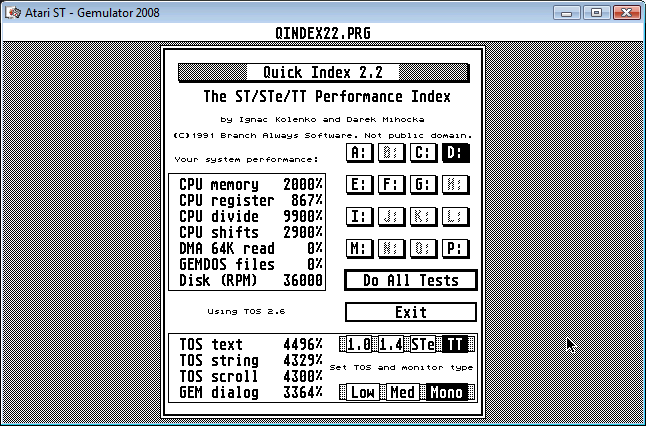
Since I obviously know the Quick Index code, let me compare the Quick Index results first. The "CPU memory" test is a memory bandwidth test which reads a small block of memory repeatedly. It's a somewhat contrived example example it measures the best case memory access speeds. It does show a tiny drop in the best case memory access speed. That means that yes, the cost of the new code sequence is probably a clock cycle or two higher than the older mapping code. The best case memory access time has therefore dropped slightly. Oh oh!
However, look at the results of the other 7 tests. They are all as fast or faster. This is the result of reducing memory latencies on the host Pentium 4, in terms of the smaller footprint it is imposing on the L1 data cache of the Pentium 4, it terms of the reduced number of hardware TLB misses on the Pentium 4, and in terms of reduced numbers of memory access faults. This shows up as faster results of the screen rendering tests, but can also surprisingly speed up CPU-bound operations, since there are still guest interrupts being simulated and guest stack accesses taking place. The new technique simply puts less of a strain on the host CPU, as well as avoiding any potential MMU-related errata.
The GEM Bench results show similar, as many of the benchmarks are within the 5 millisecond margin of error (due to the resolution of the 200Hz Atari ST timer interrupt). There are two glaring anomalous results I need to explain. The first is the negative value of the "Average". That is ignorable, as it is the result of an integer overflow in the internal mathematics that GEM Bench uses to average all the test results. Even in 1993, nobody expected any Atari ST code to ever be running at 20, 30, even 50 times the speed of a 33 MHz 68030!
The result that is of value are the three numbers for "RAM Access", "ROM Access", and the average "CPU" number. They are significantly slower than in the previous implementation, something that at first alarmed me. The RAM and ROM access benchmarks weigh heavily on the overall average CPU number as well, causing that number to drop in half! Yikes!
The cause of this is the way that Ofir wrote his memory bandwidth code. Whereas Quick Index reads the same small buffer repeatedly, Ofir chose a more realistic case which walks a much larger memory buffer and reads data at, quite ironically, 260-byte increments. That means that each such memory access maps to a different hash table slot, and because his test buffer is much larger than 64 kilobytes, each lookup fails the address match! Had he used a smaller span, which is more realistic of memory copy code and string copy code, the software TLB hit rate would have been much higher. Ofir wrote his code to use a large span so as to specifically avoid the effects of any data cache on the 68030 or 68040. This same technique is used on the PC to measure memory latency by using a large stride to force L1 and L2 cache misses.
What Ofir's test exposes is that need to further tune the slow path of the memory mapping, the hardware emulation function which is called when the fast lookup misses. This is why Gemulator 2008 is still in beta, because there are still performance benefits to be squeezed out here.
Overall I am satisfied by these and similar results on the Mac emulation side. It proves that without a loss in speed on real world code (which tends to have good data locality and thus fewer translation misses than some synthetic benchkarms) one can completely eliminate hardware based memory protection and memory mapping and go with this emulation based scheme.
Accelerating Virtual Machines
Something I would like to point out about the code sequences that I have just described is that they are using very simple and very common integer operations available to any 32-bit CPU these days. They do not require MMX or SSE or any other funky new instruction set extension that either AMD or Intel has added in the past 20 years. This could would have worked just fine 20 years ago on a Compaq 386 running MS-DOS.
For 20 years now, AMD and Intel have been bombarding developers with dozens of new MMX and SSE instructions that most code never uses. All sorts of claims about faster this and faster that, with the latest marketing focusing on the useless hardware virtualization technology. Both companies have grown the complexity of their CPUs immensely, added large L1 and L2 caches, large TLBs, even added hidden layers of caches on top of cache, all to make hardware based memory protection and translation faster.
I have been arguing that much of this is unnecessary, as many of the "unsafe code tax" issues could be reduced or eliminated if the companies had only focused their attention to accelerating code that people actually write. Developers do use hash tables a lot. Developers do use bounds checks a lot. They do bit manipulation operations a lot. With the both 68040 and PowerPC architecture have had handy bitfield insertion and extraction instructions for years, the 64-bit x64/AMD64 architectures still lack even a basic bitfield extraction instruction. The MOVZX trick I use it about as close as you get to efficiently extracting some bits out of a register.
So imagine if AMD or Intel would devote just a tiny bit of effort to speed up these basic arithmetic operations. Imagine if we had a true PowerPC-style "shift-and-mask" bitfield extraction instruction. It would allow the 256*256 software TLB to be slightly larger. Perhaps with 1024 entries of 512-byte pages or some such thing. It would allow for greater versatility in writing some pretty basic and common code sequences.
Let's look at my latest address translation and guest memory access code again:
movzx eax,ch
mov edx,ecx
add edx,2
xor edx,pagetbl+eax*8
test edx,0FFFF0101h
mov edx,pagetbl+eax*8+4
jne ReadHWLong
xor edx,ecx
movzx eax,dword ptr [edx-3]
I can live with the MOVZX for now, I will not harp on that today. The next two instructions: MOV/ADD, almost any other CPU architecture has a 3-operand instruction such that I could write an instruction such as "ADD EDX,ECX,2". This is in fact an instruction form I proposed in my VX86 extensions. x86 does contain a special case of the LEA instruction where one can write code such as "LEA EDX,[ECX+2]" to do exactly what I am asking for. The problem is, my benchmarks show that using LEA in place of MOV/ADD is actually slower. My guess is that LEA must take the 3-cycle address generation data dependency penalty. Literally, if I replace MOV/ADD with LEA and re-run the Gemulator benchmarks, they are slower. It would be great if AMD and Intel fixed their CPUs such that the LEA instruction was as fast as a plain integer ADD instruction.
Here is where I actually wish for a new instruction. If you think about what the XOR/TEST sequence actually is, it is a "fuzzy compare". It is comparing a register to a memory location and looking for equality in only some of the bits. Wouldn't it be great it x86 had a 3-operand fuzzy compare instruction, say, CMPFZ, which I could then rewrite my code with as:
movzx eax,ch
mov edx,ecx
add edx,2
cmpfz edx,pagetbl+eax*8,0FFFF0101h
mov edx,pagetbl+eax*8+4
jne ReadHWLong
xor edx,ecx
movzx eax,dword ptr [edx-3]
Intel did in fact define such a 3-operand instruction for in IA32 for 32-bit multiply instructions. There is existing precedent for this reg-mem-imm32 instruction form.
Ideally, AMD or Intel could go even one step further and just give us acceleration instructions specifically aimed at software TLB implementations. Intel did a long time ago introduce the XLAT instruction for doing 8-bit table lookups. if you have never encountered the XLAT instruction, here is exactly what it says in the manual: "XLATB Set AL to the contents of DS:[rBX + unsigned AL]" - AMD Architecture Programmer's Manual, Volume 3
In other words, the BX, EBX, or RBX register (depending on the mode of execution) is a pointer to a lookup table. AL is an index into that table. XLAT reads that table entry and returns the result in AL. Hmmmm, HMMMMMM! XLAT is just a slightly simpler version of what we need!
What is XLAT was extended to the same reg-mem-imm instruction form as the fuzzy compare which I just described, as well as to support 16-bit, 32-bit, and 64-bit lookups. This new XLAT2 instruction keeps EBX as the implicit pointer to the lookup table, and performs a conditional table lookup. In other words, this would be the new code:
movzx eax,ch
xlat2 edx,[ecx+2],0FFFF0101h
jne ReadHWLong
xor edx,ecx
movzx eax,dword ptr [edx-3]
If other parameters, such as the bits used to extract the table index (which uses the MOVZX instruction) and the second XOR were implicit, the code could literally end up looking like this:
xlat2 edx,[ecx+2],0FFFF0101h
jne ReadHWLong
movzx eax,dword ptr [edx-3]
You may think I'm crazy to suggest that Intel add this XLAT2 instruction, but is this any more crazy like some of these obscure SSE4 and SSE5 instructions that our coming our way? AMD and Intel microprocessors already contain such a hardware address hashing mechanism, it is called the TLB (the Translation Lookaside Buffer). Since I have demonstrated how hardware memory management can be eliminated, why not take that TLB hardware that is already there and explicitly expose a form of TLB to the programming model for general purpose use? Whether it be a table in memory that is implicitly pointed to by a registers (thus allowing for multiple software TLBs to be used simultaneously) or the actual hardware TLB which a virtual machine could use.
In either case, software-only memory sandboxing of memory could be implemented with just a 2-instruction code bloat in the virtual machine if such an XLAT2 instruction was provided. At the very least the fuzzy compare instruction CMPFZ could be trivially implemented in hardware.
Loose Ends
Over the summer I started evaluating a number of open source and commercial virtual machine products, from PearPC which emulates a Power Macintosh to PC-on-PC virtual machines such as Bochs, QEMU, Virtual PC 2007, VMware Player, PTLsim, and VMware Fusion. As I mentioned a few weeks ago, I have selected the orphaned open source project PearPC and the active open source project Bochs as the two virtual machines that I will be devoting effort to improving and merging them together along with my own Gemulator/SoftMac code bases into a single code base. The end product will be an open source Virtual Execution Runtime which will not only demonstrate the principles of emulation which I have discussed for these past week, but will disprove the common myths about virtualization and direct execution.
I have already made some significant progress in cleaning up the Bochs code and removing code which was clearly written based on some of these myths. Comparing Bochs, which is strictly a C++ based interpreter, to QEMU and Virtual PC right now looks pretty hopeless. Bochs 2.3.5 (which was just released last month) boots a 32-bit Windows XP virtual machine in about 3 minutes and 20 seconds. My goal is to cut that boot time in half by end of this year, or roughly from 200 seconds to 100 seconds. So far I have cut the time to under 3 minutes, but obviously still have a long way to go. QEMU and Virtual PC 2007 for example, booting almost identical Windows XP virtual machines, each boot in under 60 seconds on the same computer (that being my 2.66 GHz quad-core Mac Pro). Does a C++ based interpreter have any chance to catch up to these binary translation and hardware virtualization based products? I certainly think so.
People have asked me why am I starting with what is currently the slowest PC emulator, Bochs, and not starting with say, QEMU, or its derivative VirtualBox, which claim to be "fast". In analyzing QEMU, I found that it takes a number of shortcuts such as not fully implementing a simulator of the full x86 instruction set in its dynamic translation engine and instead relying on direct execution methods. This results in inaccurate simulation of certain code sequences which Bochs simulates perfectly, and thus lacks the infrastructure necessary to support my vision of host-independent virtual machines that freely move around the internet. The dynamic recompilation mode delivers speed which I've measure to be at about a 30x to 50x slowdown, which is disappointingly slow for dynamic binary translation. Bochs may be a slow interpreter now, but it is extremely accurate and serves as a stable starting point. The code base is also rather clean and maintainable, and from what I've found so far, ripe for optimizations. Every few weeks from now on I will plot the progress of the Bochs rewrite.
How would you tackle this problem? This is no minor "gee, let's speed up the code by another 10% and ship it" weekend programming exercise. This is a matter of getting about a 300% performance speedup just to match the speed of QEMU, and then possibly another 1000% speedup on top of that to rival Virtual PC and VMware products. Is everything that I have been saying about binary translation doomed? Buahahaha, you will have to keep reading next month. For now, familiarize yourselves with these various emulators:
Bochs: (http://bochs.sourceforge.net/)
PearPC: (http://pearpc.sourceforge.net/)
PTLsim: (http://www.ptlsim.org/)
QEMU: (http://fabrice.bellard.free.fr/qemu/)
VirtualBox: (http://www.virtualbox.org/)
Virtual PC: (http://www.microsoft.com/windows/products/winfamily/virtualpc/default.mspx)
VMware Fusion: (http://www.vmware.com/products/fusion/)
It was pointed out to me after last week's posting that there is in fact a company (http://www.moka5.com/) striving to deliver as they call it "freedom computing" - the concept of virtual machines that can stream down to you across the internet and even be patched on-the-fly. The technology seems to have been recently announced at VMworld and is still in beta, so it will be interesting to see where it goes and how host-independent it ends up being. With the price drop of the Sony Playstation 3 to $399 this month, creating virtual machines that seamlessly hop across the internet to bring Mac OS or Windows to traditionally non-PC devices such as the PS/3 is the holy grail of virtual machines that I am aiming for.
Finally, in follow-up to my comments last week I did send an inquiry off to VMware asking the specific restrictions of VMotion. I did received some information which was presented at last month's VMworld 2007 but that information has not apparently been posted publically yet. This link (http://www.vmware.com/communities/content/vmtn/vmworld/) so far still only has last year's presentations. I will wait until the particular information is posted publically before I say any more about VMotion. This concludes the postings for October. Next Monday the 29th I will take a break to play around with the long-awaited retail release of Mac OS X 10.5 "Leopard" which comes out in mere days. My next posting will be on November 5th, which will be a continuation of looking at ways to further optimize virtual machine code. Keep those comments and ideas coming by emailing me at darek@emulators.com.