ARM64 Boot Camp
(c) 2024 by Darek Mihocka, founder, Emulators.com.
updated January 23 2024
ARM64EC (and ARM64X) Explained
Probably the most confused looks I get from other developers when I
discuss Windows and ARM64 is when
I used the term "ARM64EC". They ask is the same thing
as ARM64? Is it a different instruction set than ARM64? How can you
tell if an application is or ARM64 ARM64EC?
This tutorial will answer those questions by de-mystifying and explaining the difference between what can be called "classic ARM64" as it existed since Windows 10, and this new "ARM64EC" which was introduced in Windows 11 in 2021.
TL;DR
In short, these are the ten quick facts you need to know about ARM64EC and ARM64X:
- ARM64EC is not a new instruction set, it uses the same 64-bit ARMv8 instruction set as used in Windows 10 for ARM, on your Google Pixel Android phone, or your Apple Silicon based Macbook. Rather, it is an alternate ABI (application binary interface, i.e. a calling convention) for ARM64 which provides interoperability with non-native binaries (a.k.a "foreign binaries") compiled for 64-bit x64.
- ARM64EC-built code is compiled in a way to make it is "Emulation Compatible", thus the name ARM64EC. ARM64EC code can easily call emulated x64 code, and vice versa, without even any source code changes since all the heavy lifting is done seamlessly by the compiler, linker, C runtimes, and the OS. Contrast this with traditional mechanisms such as PInvoke or JNI where interoperability explicitly requires source code modifications.
- ARM64X is an ARM64 eXtension to the standard Windows PE (portable executable) file format allowing ARM64 code and emulated Intel x64 code to interoperate with each other within the same binary - differentiating it from the "either-or" approach of a fat binary. This is called a hybrid binary. ARM64X format is backward compatible with older OSes such as Windows 10 for ARM and older debuggers and development tools, although the interoperability extensions will be ignored and only the ARM64 codebytes will be exposed.
- Almost every 64-bit binary that ships in Windows 11 on ARM is built as ARM64X, allowing them to be used by both classic ARM64 applications and emulated x64 applications.
- ARM64EC functions compiled to ARM64 bytecode export an Intel compatible entry point called a Fast Forward Sequence which contains a stub of x64 codebytes. The FFS is compatible with GetProcAddress() allowing legacy Intel applications and games to do things like hotpatch NTDLL.DLL and other system binaries - completely oblivious to the fact that the body of the function is actually ARM64. Think of an ARM64EC function as an ahead-of-time precompiled x64 function with an ARM64 body and an x64 skin.
- Visual Studio 2022 versions 17.4 and later officially support ARM64EC code generation and emitting ARM64X binaries. Earlier versions of VS had partial and incomplete support - don't use them! Paired with Visual Studio you should use build 22621 of the Windows SDK when building ARM64EC applications. Preferably you should always use the latest Visual Studio and SDK available, which is currently Visual Studio 2022 17.8.5 and Windows SDK build 26020 at the time of this writing.
- The Windows 11 for ARM kernel maintains a per-process "EC bitmap" which marks every single 4K page of address space as either native or foreign. This bitmap is updated any time an EXE or DLL is loaded or unloaded into the process, address space is allocated or freed, or the app itself is setting up a JIT buffer and wishes to specify which architecture it will be jitting for. The address space of a process can be probed at run time (using the RtlIsEcCode() function exposed by the Windows SDK) to determine whether a given address is foreign or native.
- 64-bit Intel x64 emulation in Windows 11 is built around ARM64X binaries and the ARM64EC interoperability. This is very different how the 32-bit Intel x86 emulation was implemented for Windows 10 where the WOW64 layer mediates the interoperability.
- With the new ARM64EC build target in Visual Studio, you can easily rebuild an x64 application as ARM64EC in a matter of minutes. This is thanks to the incremental porting that is made possible by the tight coupling of ARM64EC and the x64 emulator, allowing you to port individual functions and leave others unported while still having a runnable working application each step of the way. Porting a large application's code to a new architecture has traditionally been an "all-or-nothing" affair requiring weeks or months of effort before the newly ported app can boot and run correctly. In some cases years, as when I was involved in the Microsoft Office port to PowerPC back in the 1990's - the end-of-to-end port took over 2 years until finally launching as Microsoft Office 98.
- ARM64EC makes use of a library called soft intrinsics (or "softintrins") which is implemented by the SDK's softintrin.h header and softintrin.lib static library (and also mostly implemented by yours truly). Softintrins allow legacy C/C++ source code that contains Intel intrinsics to compile with the native ARM64 compiler, even supporting such Intel intrinsics as __cpuid(), as well as about 500 SSE intrinsics - this makes incremental porting possible. A piece of source code, whether compiled as x64 and emulated, or whether compiled as ARM64EC, will behave identically at runtime as portion of it are incrementally ported.
With these quick facts in your head you should be able to now make sense of Microsoft's ARM64EC documentation which can be a little daunting at first without this background. Or keep reading this tutorial as I take you into a deeper dive of how this all works under the hood and what some problem areas are.
As one of the engineers at Microsoft who along with my colleagues Pedro and Pavel and few others helped architect and implement ARM64EC I can give you my front row perspective of what ARM64EC is, how and when to use it as a developer, the thought process behind why we went down a different design path that had been used in previous emulation implementations, and which outstanding bugs still keep me awake at night.
Let's rewind a few decades. Back in the 16-bit days of Windows 2.0 or 3.1, the Windows distribution was pretty simple: the OS was installed into a directory called C:\Windows and most of the user mode system components ("the system DLLs") lived in the subdirectory C:\Windows\System. This approach works great when the CPU and the OS only support one single ISA (namely 16-bit 8086). But what happens then when your CPU supports some new instruction set and mode of execution (e.g. 32-bit protect mode introduced with the Intel 80386) and you want to release an OS such as Windows NT which supports both 16-bit and 32-bit Intel binaries?
There are several options when an operating system is being ported to a new architecture (such as 32-bit x86, 64-bit x64, or ARM64) and needs to deal with multiple instruction sets and foreign binaries:
- Do nothing. We already know that Windows RT had no foreign binary support, provided only a limited set of native ARM built-in apps, and required third-party developers to port their applications to ARM if they wanted to run on Windows RT at all. When not enough developers bought in on this (as happened with RT) the OS ended up being of little value to paying consumers and eventually died.
- User mode emulation only. Linux users are familiar with user mode emulation via QEMU (and nowadays even Rosetta 2). Emulation allows something like an ARM64 distribution of Linux to run an ELF binary compiled for say ARM32 or x86. QEMU or Rosetta act as both the binary loader and the virtual CPU which emulates that foreign binary. System calls get "marshalled" or "thunked" to the native host OS since the kernel mode and kernel drivers themselves are native and not emulated. This method is one way I've tested QEMU again Rosetta and Microsoft's emulator - by writing little x86 or x64 test binaries and running them under QEMU's emulation to see how accurately it compares.
- Fat binaries + user mode emulation. This was and still is Apple's approach every time they transitioned CPU architectures - from 68K to PowerPC, from PowerPC to Intel x86/x64, and from Intel x86/x64 to ARM64. Their "fat binary" format contains multiple "slices" of code, each slice containing bytecode for a different ISA (such as PowerPC, x86, or ARM64). Most of the operating system itself is compiled as fat binaries. When a non-native application is launched the OS (in their case macOS) will invoke an emulator (the 68020 emulator, Rosetta, or Rosetta 2) to run the foreign slices of each fat binary. As the name implies, _fat_ binaries are larger than just a pure native binary, since they contain two even three slices of code. This approach fattens up the disk footprint of the entire OS and makes distribution of apps fatter as well. One upside of fat binaries (or "Universal Binaries" as Apple calls them) is that the end user only sees one binary and need not concern themselves over which architecture binary to download.
- Multiple binaries + user mode emulation. This has been Microsoft's approach for over 30 years since the Windows NT days. Microsoft does not use fat binaries; instead it separates binaries of different architectures and places them in separate subdirectories. i.e. Microsoft's approach puts multiple variants of the same binary (one variant for each different ISA) into different subdirectories. When Windows 10 for ARM launched in 2018 it contained no fewer than 3 copies of most OS binaries - one set of directories for native ARM64, one set for 32-bit ARM32/Thumb2, and one set for 32-bit x86!
Let's look deeper at Microsoft's past implementation of foreign binary support.
When Windows NT and Windows 95 launched in the 1990's, both added new C:\Windows\System32 subdirectory containing (no surprise) 32-bit system DLLs and the 32-bit kernel. At this point there were two variants of the system DLLs - one 16-bit and one 32-bit. Only 32-bit binaries were considered native, while older 16-bit MS-DOS and "Win16" binaries were considered foreign. Microsoft created two subsystems called NTVDM and WOW (or "WOW32) for running legacy MS-DOS and Windows 3.1 binaries respectively. The reason 16-bit code is considered foreign is that on a 32-bit operating system you cannot just load a 16-bit binary and run it directly in 32-bit mode. You have to sandbox and emulate the 16-bit code in some way. On Intel processors, there is a hardware sandboxing mode which allows direct hardware context switching from 32-bit mode to 16-bit mode and back. So in effect "emulation" of 16-bit mode on 32-bit Intel processors is really done in hardware and microcode; with occasional "trap-and-emulate". This hardware sandboxing functionality has been in use right on through to Windows 10 until all the old 16-bit support was dropped in Windows 11. This is not surprising since the long-term roadmap for Intel seems to involve completely dropping hardware support for 16-bit mode and possibly even 32-bit mode.
So far so good - System is for 16-bit binaries, System32 is for 32-bit binaries. One could naturally assume that a 64-bit OS would then some day add a C:\Windows\System64 directory, right? Wrong!
For one reason or another, Microsoft chose to keep the System32 subdirectory as the fixed location of the native system binaries. So what Microsoft did in 64-bit Windows XP, 64-bit Windows 7, right on up to today's 64-bit-only Windows 11 is that the 32-bit binaries got moved to a new C:\Windows\SysWOW64 directory, while new native 64-bit system binaries were placed in the existing C:\Windows\System32.
Got that? WOW64 == 32-bit binaries, and System32 == 64-bit binaries! For Windows 10 and 11 on ARM there is even third subdirectory C:\Windows\SysArm32 which as the name suggests hold the 32-bit ARM/Thumb2 system binaries. And yes, the 32-bit x86 binaries in C:\Windows\SysWOW64 are identical both in Intel distributions of Windows 11 and ARM64 distributions of Windows 11, since 32-bit x86 is considered "foreign" on both.
You can see this in action quite easily. All Windows 11 builds have a new column in Task Manager called "Architecture" which displays not only the "bitness" of a given running process (32-bit or 64-bit), but also its ISA (instruction set architecture). If you are running on an AMD Ryzen or Intel Core i7 system, the distinction between "bitness" and ISA is moot, since you are either running a process as a 32-bit x86 process or a 64-bit x64 process; there are no other combinations. For example on my AMD 5950X machine if I bring up Task Manager and go to the "Details" tab, you can see that I have several instances of the command line prompt (CMD.EXE) running as 32-bit processes, and several running as 64-bit processes:
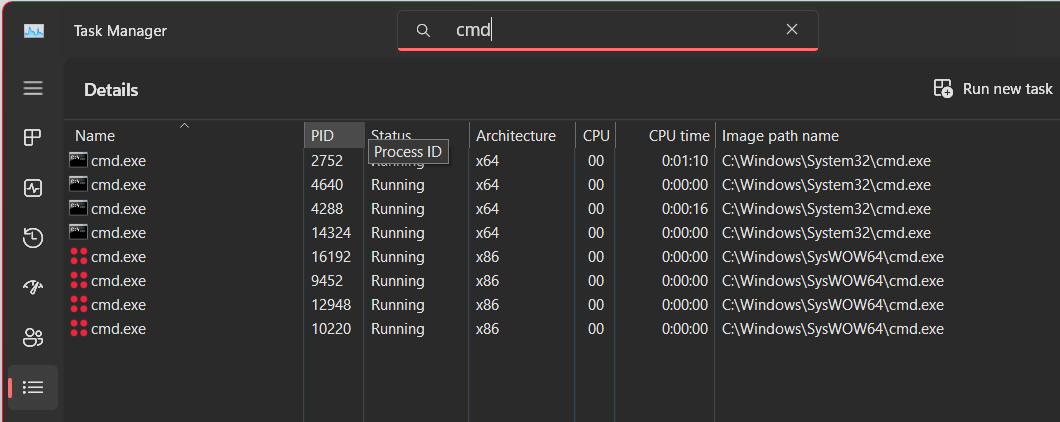
Even in say XP or Windows 7 which lacked the Architecture column you could tell based on the "Image path name" column (and as you can see above with CMD.EXE) by which directory path the binary is in. The 32-bit instances of CMD.EXE launched from the C:\Windows\SysWOW64 directory, while native 64-bit version launched from C:\Windows\System32 as I described above.
There is neat way to launch a specific architecture of, say, the command prompt when multiple variants of the binary exist. The Windows START command for launching new processes has an option /MACHINE to force a specific architecture of the new process:
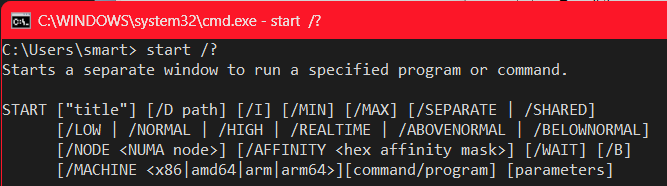
Notice that it accepts "x86" "amd64" "arm" and "arm64" and there is no "arm64ec" since that is not a separate architecture!
Pro tip: Microsoft is often inconsistent with its naming of architectures across its various tools, using "amd64" and "x64" interchangeably, and "arm" "ARM32" and "Thumb2" interchangeably. So just understand that amd64 or (AMD64) == x64, and arm (or ARM) == ARM32 (which on Windows is really Thumb2). Got it? :-)
So what does it look like if you try to launch the 4 different architectures of CMD.EXE on an ARM64 device? Let's try it! Using Windows 11 SV2 Nickel on my Samsung Pro 360, I launched 4 CMD.EXE instances using each of the 4 different /MACHINE options. 4 command line windows opened up and looked identical, so let's take a look at what Task Manager showed:

As expected, the native ARM64 instance launched from C:\Windows\System32, the emulated x86 instance launched from C:\Windows\SysWOW64, and the 32-bit ARM instance launched from C:\Windows\SyArm32.
But look at the supposed x64 instance, it shows up as "ARM64 (x64 compatible)" and claims to be the same binary as the native ARM64 version. This is clearly NOT the usual pattern of adding yet another new subdirectory of additional binary files. In Windows 11 you will not find, say, a C:\Windows\SysAmd64 subdirectory. Why is that?
On factor that we considered is that many apps and setup programs hardcode the "System32" path and blindly copy their own binaries or open handles to system DLLs (such as USER32.DLL, KERNEL32.DLL, MSVCRT.DLL etc.) using the hardcoded C:\Windows\System32 path name. For things to work correctly with foreign binaries, the WOW64 emulation layer magically performs some hidden file redirection, changing the path name from C:\System\System32 to either C:\System\SYSWOW64 or C:\System\SysArm32 as appropriate for x86 and ARM32/Thumb2 architectures respectively. WOW64 has been doing this since the days of Windows XP, and also invokes the correct 32-bit emulator for each architecture (either the hardware sandbox for x86 on Intel hosts, a different hardware sandbox for ARM32 on ARM64 hosts, or the xtajit.dll binary translator for ARM64 hosts).
The kernel team were dreading adding yet another architecture to WOW64 and having to have yet another set of file redirections to worry about. Worse, the concept of WOW has for 30+ years always implied a smaller bitness - i.e. 16-on-32, or 32-on-64. The Windows code base was just not set up for the concept of WOW sandboxing 64-on-64 bitness. Worse, many applications frequently call the IsWow64Process() function to determine if a process (even itself) is running under WOW64, and if so they falsely assume a) that the sandboxed process under WOW64 is 32-bit, or b) that the host CPU is AMD/Intel x64. Both these assumptions would clearly be wrong and would break many applications if x64 emulation was implemented as a WOW64 client. Using the WOW approach was off the table. And similarly fat binaries were off the table because this had never been done before in Windows and no toolset could easily support this. This seeming dead end is one reason work on 64-bit emulation kept getting put off because the existing methodology just wasn't going to work.
Obviously we solved the problem and today even the Microsoft Office on ARM64 is built using ARM64EC for interoperability with older Office plug-ins compiled for Intel x64. You can easily verify in Task Manager that all of the Office applications show up as "ARM64 (x64 compatible)" rather than just "ARM64":

So does that mean that CMD.EXE and the Microsoft Office on ARM64 are not native ARM64? Are they emulated x64? Let's go back to about mid-2019 to...
So if WOW64 is off the table, file redirection is off the table, and fat binaries are off the table, what else is left?!?!? We already know this is not entirely an unsolved problem, since User Mode QEMU as well as Wine already exist today on Linux to run non-native user-mode applications written for other CPU architectures, and/or for Windows. The "non-native user-mode application" is the key similarity between those use cases and the emulation of x64 in Windows.
I had alread been prototyping a user mode 64-bit x64 interpreter called xtabase to try to model a 64-bit user mode emulator. I went down a similar path as user mode QEMU: I compiled the x64 interpreter as a native ARM64 binary and then used it to manually load and fix up a x64 test binary, which it then starts interpreting as x64 at the binary's entry point. The Windows OS is completely oblivious to what is happening since the emulator is doing all the work. This is great for running super trivial toy binaries, since Visual Studio allows you to compile and build a single C function as a standalone binary. If you have trivial test code such as an 8queens benchmark which takes no input and simply returns a single integer result, this approach is perfect and allowed me to have a working x64 interpreter up and running in a few months, capable of running small test functions to validate correctness.
But what happens when that x64 binary goes to call printf(), malloc(), GetTickCount() or some other runtime function that needs to be found in another binary such as UCRTBASE.DLL or KERNEL32.DLL? I used the common trick of function call marshalling, which is similarly used by user mode QEMU or any time managed code in .NET or Java calls out to native system code. xtabase takes the function call arguments (or in the case of GetTickCount, no arguments) and then makes a native function call to the target function. When that native function returns, the return value is then placed back in the emulated state and emulation continues at the point past the call.
To get a fairly simple Windows "hello world" x64 binary to emulate in this fashion only requires marshalling about 40 or so C runtime and Win32 functions: there is the obvious call to printf(), and if you fudge the entry point of the test EXE to directly point to the main() function itself, then yes, you only have to marshal the printf() call. To run something more complex or a benchmark you likely need to also marshal malloc(), free(), GetTickCount(), fopen(), fread, and handful of other common APIs. This way I was able to bootstrap up to running small benchmarks which actually read the clock and computed performance and displayed output to the screen.
To truly be able to run an unmodified "hello world" you need to also marshal all of the system calls that the C runtime startup code calls during initialization on its way to eventually calling the main() function. And then there is the C runtime shutdown code which implicitly gets called when main() returns - think exit() function and a bunch of file close operations. So that is where the whole 40 functions in total comes about. And this is basically what Wine does on Linux - over the years they just marshal more and more Win32 functions over to Linux system calls, to where today Wine is able to run many Windows 10 applications and even applications that rely on DirectX.
Function call marshalling is also done by WOW64 layer itself when it has to marshal arguments between 32-bit user mode and 64-bit system calls. Arguments such as pointers need to be widened from type __ptr32 to type __ptr64, and similarly "pointer sized integers" such as uintptr_t and intptr_t arguments need to be zero-extended and sign-extended. Anyone who's written a Window message loop is familiar with the SendMessage() function, but how many of you realize that the width of the lParam is not fixed? The lParam's argument's LPARAM type is actually a pointer-sized integer and thus has to be extended when being passed from 32-bit mode to 64-bit mode, as you can see in its definition in the Windows SDK:

Another aspect of 32-bit emulation in WOW64 is that two stacks have to be used: - the 32-bit x86 stack where everything is 4-byte aligned and pointers are 4 bytes wide, and the 64-bit native ARM64 stack which is (by hardware design) 16-byte aligned and pointers are 8 bytes wide. 32-bit x86 code and native ARM64 code cannot share data in memory or even on the same stack because the data layouts are different. All data structures have to be marshaled as well, not just the pointers to them.
Emulating 32-bit on a 64-bit system is thus very messy (and why it took many years to get the initial 32-bit x86 emulation on ARM64 to work well). But I wasn't aiming to emulate x86, I was modeling x64. 64-bit applications have their own differences and calling conventions as per this table comparing 32-bit x86, 64-bit x64, and 64-bit ARM64 and you can see there is quite a difference:
x86 x64 ARM64 __cdecl function argument passing on stack, caller pops stack first 4 in registers, the rest on stack first 8 in registers, the rest on stack __stdcall function argument passing on stack, callee pops stack first 4 in registers, the rest on stack first 8 in registers, the rest on stack __fastcall function argument passing 2 32-bit in registers, the rest on the stack first 4 in registers, the rest on stack first 8 in registers, the rest on stack argument registers ECX, EDX RCX, RDX, R8, R9 X0, X1, X2, X3, X4, X5, X6, X7 return value registers EAX, EDX RAX, RDX X0, X1 stack alignment 4 bytes 16 bytes 16 bytes stack pointer size 4 bytes 8 bytes 8 bytes program counter size 4 bytes 8 bytes 8 bytes pointer size 4 bytes 8 bytes 8 bytes
Since the x64 ABI was developed a good 10 years after x86, it has some nice simplifications which also carried over to ARM64. One thing should be popping out at you right now, which is that at the C/C++ function call level...
ARM64 and AMD64 (x64) calling conventions are extremely similar!
As I was writing marshaling functions for x64-to-ARM64 I came to realize that many of those functions are effectively a NOP. For as long as fewer than 5 function arguments are being passed and there is no funky passing of structures or floating point values, x64 calling convention and ARM64 calling convention have a remarkable amount of common overlap. Simple calls like GetTickCount() and GetProcessId() and GetLastError() which take no arguments and just return a value really don't need any marshalling. Functions which do take arguments such as SetLastError() also require no marshaling since no memory is touched, no stack is modified.
So I found that I didn't have to write a separate marshalling wrapper for each of the 40 or so C runtime and Win32 functions that I needed for "hello world". The emulator could instead assume a default where a function takes no more than 4 integer arguments and returns an integer. This meant that my xtabase emulator could call directly into function entry points of the native ARM64 binaries in C:\Windows\System32 and pass pointers and data structures as-is - no separate x64 binaries required, no fat binaries requires, no WOW64 layer.
There is also an obvious 1:1 register mapping that arises from looking at the calling conventions and which registers are used to pass arguments to function calls and return values: RCX->X0, RDX->X1, R8->X2, R9->X3 and then on return X0->RAX, X1->RDX. Notice that X1 and RDX even map to each other in both directions.
So Pedro and I started thinking...
- what if there was no WOW64 layer required?
- what if there was no additional directory of binaries required?
- what if there was no need the original x64 binaries at all?
- what if there even was no second stack and instead x64 and ARM64 shared the same stack?
- what if there was a nice 1:1 mapping of x64 registers to ARM64 registers so no marshalling was required?
Again, at this point this was not purely hypothetical because I had a working x64 interpreter running as ARM64 code that was able to run simple test binaries like "hello world" and the "8queens" benchmark. Memory allocation, timing functions, screen output was all working. But that last point - the 1:1 register mapping - is extremely critical for cases that involve exception handling and stack unwinding filters or when an app calls GetThreadContext() or SetThreadContext(). In those scenarios a data structure called CONTEXT is passed around, which as you can see by peeking at winnt.h the x64 CONTEXT is quite different layout and size than the ARM64 CONTEXT or for that matter the x86 CONTEXT. This implies that some kind of WOW64 marshalling layer would still be require to translate the CONTEXT layouts back and forth. But what does that even mean? How do the 80-bit x87 floating registers map to ARM64 state? How do ARM64's 32 128-bit NEON registers map to x86's 16 128-bit SSE registers? How do the arithmetic flags map? We were trying to pair a square peg with a round hole.
What we really needed was a complete 1:1 register mapping. So far, all we had was 4 registers that sort of lined and made toy test binaries run. We can trivially also map the stack pointers (RSP <-> SP) and the program counters (RIP <-> PC). And we can sort of map the NZVC (Negative, Zero, Overflow, Carry) arithmetic flags to Intel's SZOC (Sign, Zero, Overflow, Carry). Progress!
When we wrote down all of the interesting x64 user-mode registers and compared against the ARM64 user-mode registers, including how wide they are and whether they are volatile (caller-save, or "scratch" registers) or non-volatile (callee-save) we little-by-little matched up more of the registers.
Fortunately ARM64 with its 32 integer registers and 32 vector registers has enough registers to fit the x64 register state (including MMX, x87, and SSE's XMM registers). If you carefully try to map volatile-to-volatile, and non-volatile to non-volatile, you come up with one possible mapping (of many) of an ARM64 emulation compatible register state:
x64 ARM64 register volatility RCX X0 volatile RDX X1 volatile R8 X2 volatile R9 X3 volatile R10 X4 volatile R11 X5 volatile ST1 X6 volatile ST2 X7 volatile RAX X8 volatile ST3 X9 volatile ST4 X10 volatile ST5 X11 volatile ST6 X12 volatile - X13 volatile - X14 volatile ST7 X15 volatile exponents 0-3 X16 volatile exponents 0-7 X17 volatile GS base X18 (TEB) non-volatile R12 X19 non-volatile R13 X20 non-volatile R14 X21 non-volatile R15 X22 non-volatile - X23 non-volatile - X24 non-volatile RSI X25 non-volatile RDI X26 non-volatile RBX X27 non-volatile - X28 unused RBP X29 (frame pointer) non-volatile ST0 X30 volatile RSP X31 (SP) non-volatile RIP PC (program counter) XMM0-XMM5 V0-V5 volatile XMM6-XMM15 V6-V15 non-volatile - V16-V31 non-volatile
Note that all of what in x64 are considered to be "scratch registers" such as RAX RCX R10 R11 etc. all map to like scratch registers on ARM64 nicely map to X0 through X8. And all the x64 non-volatile callee-save registers which have to be preserved across function calls are also mapped to like registers - RSI RDI RBX RBP R12-R15 nicely map to the X19-X29 non-volatiles.
There is some funny register shuffling that you might notice:
X18 is special, it points to the thread's environment block (TEB) and is constant to a give thread. It is equivalent to the FSBASE register in x86 or the GSBASE register in x64. So this register can be derived.
X28 is also special, as Microsoft's C/C++ compiler (and thus most Windows binaries and Microsoft apps) never makes use of this register! Try it, single-step through any ARM64 native code generated by Visual Studio and you'll never see the x28 register show up.
X16 and X17 are funny, as they contain the 8 16-bit exponents of the x87 floating point registers. Since the shared MMX/x87 state is volatile and not preserved (and rarely if ever even used in 64-bit x64 code) the fact that their layout is munged up like that is really not important. X16 and X17 are normally used as scratch registers for indirect jumps to DLLs, so by design they get trashed during most calls anyway.
The problem is there are some gaps. ARM64 has 2 too many scratch registers, 2 too many non-volatile registers, and obviously double the number of vector registers. This means that X13 X14 X23 X24 and V16-V31 cannot be mapped to x64 state!
V16-V31 could very easily be mapped if Microsoft's emulator supported AVX/AVX2 and thus 16 256-bit YMM register state would map nicely to 32 128-bit NEON register state, but alas, they choose not to support the larger AVX state at this time. (To this day in 2024, Microsoft still has not support for AVX or AVX2 instruction or the YMM register state in the emulators).
Now armed with our (mostly) 1:1 register mapping, it was possible to take the existing x64 CONTEXT structure which has been around for 20 years and re-imagine it as an ARM64 (but emulation compatible) context structure. Starting with the Windows 11 SDK, the ARM64EC_NT_CONTEXT exists in the winnt.h header file as its own data structure. But it is not a different data structure from the original x64 CONTEXT structure - the layouts are identical. Here is a small sample from winnt.h (build 26020) showing the fields using the ARM64 register names in ARM64EC_NT_CONTEXT and the layout of the Intel integer registers in the x64 CONTEXT:
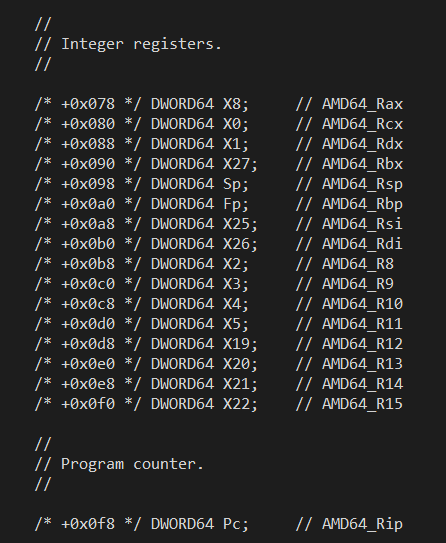
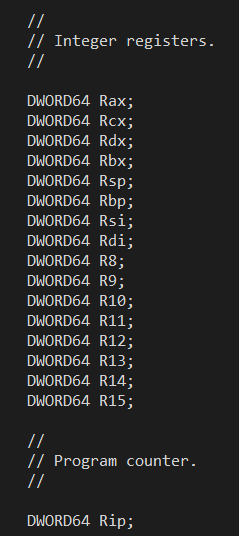
The layout of the two states is intentionally identical by design! That was the whole point of the register mapping exercise - to make x64 and ARM64 appear nearly identically in functionality when compiling C/C++ code.
What this means for interoperability is that emulated x64 code can raise an exception which can be caught either by other x64 code, or by newly ported ARM64EC code. When each examines the context structure they are both seeing x64 context layout even though the ARM64EC is using ARM64EC_NT_CONTEXT. So whether the exception filter is looking at the Rcx or X0 fields does not matter - they are the same byte offset into the structure. Rip and Pc are the same offset. Rsp and Sp are the same offset. R15 and X22 are the same register at the same offset in the structure. And so on.
The key difference when building ARM64EC vs. ARM64 code
I hope you have now realized that ARM64EC is a way of compiling ARM64 native code in a way which makes that ARM64 code interoperable with emulated x64 code in the same process. An emulated binary can call CreateFile() and not worry which architecture CreateFile() is implemented as. And if the same x64 code is now recompiled as ARM64EC it should work identically, including that "sizeof" keyword returns the same values for the same data structures, whether x64 and ARM64EC.
Under the hood, a lot of this is made to work using C preprocessor tricks. The C/C++ compiler itself knows nothing about Windows data structures, so the way we ensure that the correct data structures get pulled in is by lying to the compiler preprocessor by pretending that we are compiling for a native x64 target, not native ARM64. This way source code (including Windows SDK header files and C runtime header files) is parsed as if targeting AMD and Intel. The resulting intermediate language (IL) representation of the parsed code is then passed through to the native ARM64 compiler back end (the code optimizer and code generator) which then emits native ARM64 instruction codebytes, not x64 codebytes!
You can see this using a Visual C/C++ compiler switch -Bd which dumps the actual switches being passed to the compiler passes (c1.dll, c1xx.dll, and c2.dll). If I open the vcvars64 x64 development environment and compile any code with -Bd added, part of the output will show the pre-defined macros being passed to the C preprocessor (using -D to define a macro), and these will include:
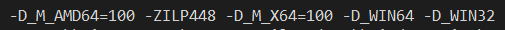
Compare this against the using the vcvarsarm64 native ARM64 compiler to target classic ARM64:

Notice the difference? Both define _WIN32 and _WIN64, which are necessary pre-defined macros to indicate that we are compiling for Win32 and compiling for a 64-bit target. By when targeting x64 the _M_AMD64 and _M_X64 (the AMD preferred macro and the Intel preferred macro are defined) while when targeting ARM64 the _M_ARM64 macro is defined.
What happens when we use the same ARM64 compiler but also now pass the -arm64EC switch?
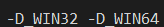
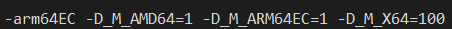
The preprocessor is told that we are targeting x64 _and_ ARM64EC, but not ARM64. If the C/C++ source code you are compiling is not "enlightened" and knows nothing about either ARM64 or ARM64EC, it will blissfully compile as if for an Intel target, even through the resulting binary will contain ARM64 code!
But if your code _is_ enlightened and you want to specifically have code paths always only execute on ARM devices, you can set up your #defines like this:
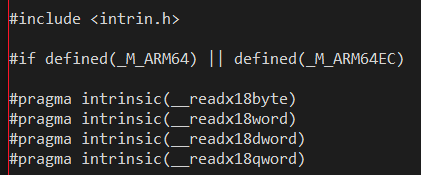
Notice in the above snippet from winnt.h that the header specifically wants to define the same ARM64-specific compiler intrinsic for both ARM64 and ARM64EC. This makes sense, since these intrinsics are only meaningful to the ARM64 code generator.
Similarly, winnt.h plays the opposite game when declaring x86- or x64-only intrinsics which have no meaning to ARM64, such as the intrinsic for Intel's INT 0x2C instruction:
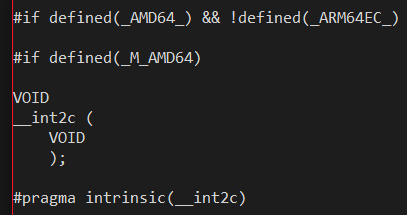
Notice how the use of !defined(_ARM64EC_) prevents Intel-only intrinsics from accidentally being passed to the ARM64 back end. You will see this particular preprocessing pattern (#if _M_AMD64 && !_M_ARM64EC) in hundreds of places throughout the C headers and Windows SDK headers where definitions specific to AMD and Intel hardware are being defined.
But the main thing I want you to remember is that to build ARM64EC targets you need to pass -arm64EC to the compiler driver (cl.exe). Pro tip: If you are using Visual Studio 2022 this will be done automatically when you add "ARM64EC" as a specific build target, as shown in the screen shot of the Xformer 10 project settings above.
So now it should make sense to you what the Task Manager meant by "ARM64 (x64 Compatible)". I have explained the what ARM64EC is, and why it is the way it is, but I have not full explained how the mixed code plumbing works.
You have probably deduced that C:\Windows\System32\CMD.EXE is built with ARM64EC, and therefore contains native ARM64 code which can be run as a native ARM64 process, or, as an "emulation compatible" process. When launched as ARM64EC, even CMD.EXE itself believes that it is running as x64. Compare the output of the set command (to dump out the environment variables) when CMD.EXE is launched as two different architectures:
start /machine amd64 cmd.exe
start /machine arm64 cmd.exe


If the main executable of the application (e.g. the CMD.EXE file) is compiled using -arm64EC, how does the OS kernel know which mode to launch it in by default? Microsoft Office is clearly launching as ARM64EC by default.
The answer turns out to be a small modification to the Windows PE file format for ARM64 binaries, an ARM64 eXtension so to speak, that we named "ARM64X". If you use the Visual Studio linker's -dump -headers command on a given .EXE or .DLL file, it will show you the architecture of the binary, a.k.a. a machine type. The machine type constants are defined in, you guessed it, winnt.h:

You can see that 64-bit AMD/Intel targets are machine type 8664, while ARM64 is machine type AA64. So when we dump the header of CMD.EXE we see:
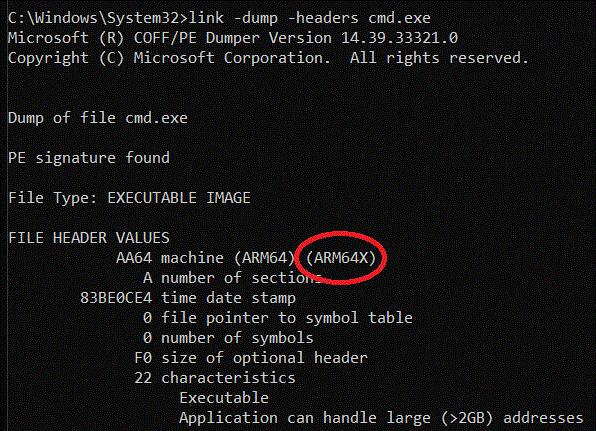
The machine type of the binary is AA64 (indicating a native ARM64 binary) but there is extra metadata which flags it as an ARM64X binary containing ARM64EC code. Therefore ARM64EC is _not_ considered to be a new machine type or a new CPU architecture. This would break backward compatibility with Windows 10 for ARM as well as probably breaking older version of debuggers and linkers and other tools since AA64 has been around for well over 6 or 7 years now. Therefore, ARM64X extends the existing AA64 ARM64 binary file format.
But watch this, let's dump the header of one of the Office binaries, such as EXCEL.EXE:
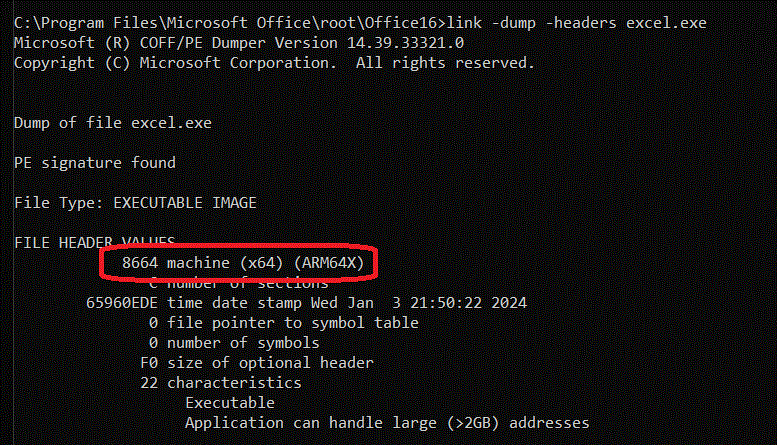
AHA! Mystery solved! It is legal to mark an ARM64X binary either as machine type AA64 (ARM64) or 8664 (AMD64/x64). Which machine type determines how the application is launched by default: AA64+ARM64X launches as plain native ARM64 process, while x64+ARM64X launches as emulated x64.
The mix of x64 and ARM64 bytecode that an ARM64X binary contains is up the developer who builds the binary - it could contain almost 100% ARM64 code with a handful of x64 entry points (this is the ideal case), or it could be at the other end of the spectrum and be practically 100% x64 code with a few ARM64EC entry points (this would be the case early in porting of a project). This is what distinguishes ARM64X from a traditional fat binary - there are not two complete versions of all code, therefore there is less code bloat than the full 2x doubling of all code, and there are advantages to taking a 100% Intel x64 codebase and incrementally porting it over to ARM64EC and eventually to full ARM64. With traditional porting of say x86 to x64, or x64 to ARM64, porting is an all-or-nothing effort, where the ported app does not build and run until every last bit of C, C++, and ASM code has been ported over. That porting effort could take weeks or months!
With ARM64EC, you can literally start by first flipping the ARM64X attribute on your existing x64 build, then start to add -arm64EC switch to your C and C++ files, and finally port over that gnarly hand-coded ASM code from x64 to ARM64.
Fast forward sequences, entry and exit thunks
I have still not explained how ARM64EC deals with the >4 arguments function call marshalling issue. This is handled by additional blocks of code which are automatically generated by the linker called: FFSs (Fast Forward Sequences), entry thunks, and exit thunks.
Let's say you compiled a function main() which calls a function work() and both are compiled as ARM64EC. The compiled main() will use a BL instruction to directly call to the work() function - "BL" is the ARM64 equivalent of the x86/x64 "CALL" instruction. But what if either main() or work() was compiled as x64? ARM64X augments the existing ARM64 binary format to handle such a situation using these three types of additional code blocks:
- An entry thunk is a small native ARM64 funclet which marshals any state coming in from the x64 caller and then calls the target ARM64EC function. i.e. it is a wrapper from x64 caller to ARM64EC callee.
- Similarly an exit thunk is a small ARM64 funclet which marshals state coming from an ARM64EC caller going to an x64 callee.
- A fast-forward sequence is an x64 bytecode entry point stub to each exported ARM64EC function, typically used in system DLLs such as NTDLL.DLL to offer "Intel-looking" entry points to what are actually native ARM64EC functions. FFSs are usually automatically generated by the linker and are typically 16 bytes in size, but can be overridden manually. If either x64 or ARM64EC code calls GetProcAddress() on an exported function, it will receive the address of the FFS - not the raw ARM64 code of the function itself. This is not unlike native-entry points in managed runtimes such as .NET where exported C# functions which may be called by native code need to export some kind of native entry point.
The purpose of the FFS is to allow legacy x64 applications that are not ARM64-aware to patch entry points of DLLs. This is very frequently done by anti-cheat code in games, by debuggers, and, well, malware! When we first brought up x64 emulation (but without proper FFSs), several video games designed for AMD/Intel processors did not work correctly because they were unable to discover valid x64 code to patch. Allowing an emulated application to believe that it is patching a real x64 function when that function is really an ARM64EC function is necessary for compatibility.
If you use Visual Studio's linker to disassemble almost any ARM64X binary, for example C:\Windows\System32\NTDLL.DLL, you will see that it begins with these similar looking code sequences which are clearly Intel code:
C:\Windows\System32>link -dump -disasm ntdll.dll Microsoft (R) COFF/PE Dumper Version 14.39.33321.0 Copyright (C) Microsoft Corporation. All rights reserved. Dump of file ntdll.dll File Type: DLL 0000000180001000: 48 8B C4 mov rax,rsp 0000000180001003: 48 89 58 20 mov qword ptr [rax+20h],rbx 0000000180001007: 55 push rbp 0000000180001008: 5D pop rbp 0000000180001009: E9 D2 9C 1C 00 jmp 00000001801CACE0 000000018000100E: CC int 3 000000018000100F: CC int 3 0000000180001010: 48 8B C4 mov rax,rsp 0000000180001013: 48 89 58 20 mov qword ptr [rax+20h],rbx 0000000180001017: 55 push rbp 0000000180001018: 5D pop rbp 0000000180001019: E9 02 9E 1C 00 jmp 00000001801CAE20 000000018000101E: CC int 3 000000018000101F: CC int 3 0000000180001020: 48 8B C4 mov rax,rsp 0000000180001023: 48 89 58 20 mov qword ptr [rax+20h],rbx 0000000180001027: 55 push rbp 0000000180001028: 5D pop rbp 0000000180001029: E9 32 9E 1C 00 jmp 00000001801CAE60
These are the individual Fast Forward Sequences. Each is 16 bytes long, each is a MOV MOV PUSH POP JMP sequence which mimics a typical x64 C function prolog (the spilling of RBP to create a stack frame and the spilling of RBX to the caller's "homeparam" area) and epilog (popping the stack frame) followed by tail-jump to another function. Two INT 3 padding bytes to round each FFS up to 16 bytes since by design an FFS must begin at a 16-byte alignment.
This sequence is not the original FFS we shipped in Windows 11 SV1 (build 22000) back in 2021. We had a simpler sequence but as it turned out this broke some video games because we used x64 instructions that their hotpatchers were not used to seeing. After a constructive email exchange with the folks at Valve we zeroed in on this much more compatible code sequence. Pro tip: This is why Windows 11 SV2 (build 22621) is the minimum version of Windows on ARM you should be using your ARM64 device. If your device came with build 22000 or even Windows 10 build 19041, or you are building using a Windows SDK prior to build 22621, upgrade it!
Notice that the only difference between each FFS is the target address of the final jump instruction. Each FFS jumps to a different ARM64EC function which that particular FFS is associated with. And if we look at the entire "link -dump -disasm ntdll.dll" output and search for those target addresses, we see for example that those first two targets very much appear to be jumping to native ARM64 code:
00000001801CACE0: A9BD7BFD stp fp,lr,[sp,#-0x30]! 00000001801CACE4: A90153F3 stp x19,x20,[sp,#0x10] 00000001801CACE8: A9025BF5 stp x21,x22,[sp,#0x20] 00000001801CACEC: 910003FD mov fp,sp 00000001801CACF0: 9403BD00 bl 00000001802BA0F0 00000001801CACF4: D10143FF sub sp,sp,#0x50 00000001801CACF8: AA0003F3 mov x19,x0 00000001801CAE20: 58000108 ldr x8,00000001801CAE40 00000001801CAE24: F805401F stur xzr,[x0,#0x54] 00000001801CAE28: 58000109 ldr x9,00000001801CAE48 00000001801CAE2C: A9042009 stp x9,x8,[x0,#0x40] 00000001801CAE30: 18000108 ldr w8,00000001801CAE50 00000001801CAE34: B9005008 str w8,[x0,#0x50] 00000001801CAE38: D65F03C0 ret
Some obvious questions should come to mind: how does the linker know to display one section of code as x64 and another block of code as ARM64? Remember, these are in the same binary. And at runtime, how does the x64 emulator know to transition from the emulated JMP instruction to what is obviously not emulated native ARM64 code?
Well, let's dive in further and attach a debugger...
The EC bitmap and the duality of context
If you use "start /machine amd64 cmd.exe" to launch CMD.EXE in emulation compatible mode and then attach the debugger to that process (use Task Manager to look up the process ID, then the -p switch to specify that process ID):

As the debugger loads up, you can see that the system DLLs which CMD.EXE references (and CMD.EXE itself) are coming from C:\Windows\System32. Notice also the loading of xtajit64.dll immediately after NTDLL.DLL loads. NTDLL is the first DLL that loads into any process and takes care of bootstrapping the rest of the process launch. When a process is launched as x64 compatible, NTDLL immediately loads the x64-to-ARM64 translator - xtajit64.dll. Pro tip: This is an implementation detail - xtajit64.dll could be loaded on demand only when emulated x64 code is hit, but for simplicity the translator is currently always loaded if there is even the possibility that emulation will take place. That also implies that an EC bitmap is also always created for any ARM64EC process.
And where we broke in NTDLL.DLL is in fact ARM64 bytecode. And if I type r for a register dump, I am shown ARM64 register state:
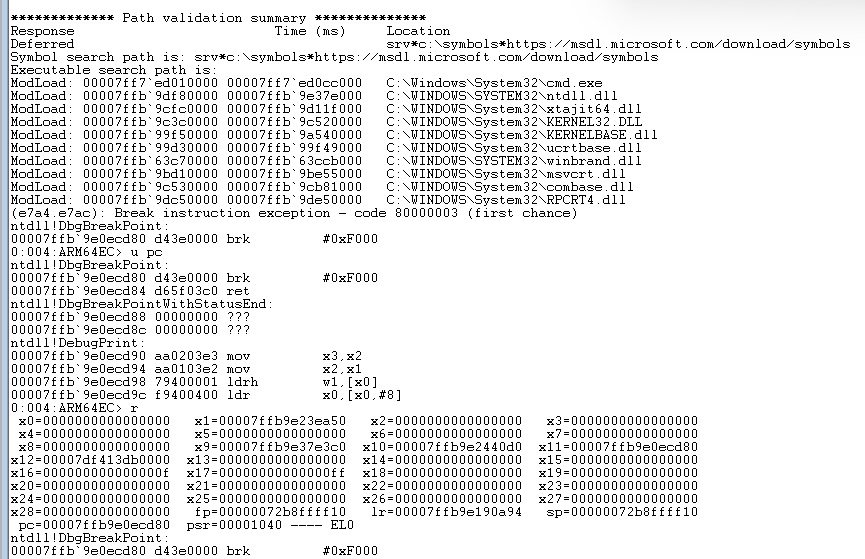
Note that X13 X14 X23 X24 X28 are zero, as they should be because they are unused in an ARM64EC process and therefore should hold no valid data.
Note also that the debugger displays "ARM64EC" at the prompt, indicating that we are in an "emulation compatible" process, not a classic ARM64 native process, even though we happen to be at a function that compiled in ARM64 bytecode.
Ok, let's exit the debugger and repeat this, but this time we will make use of the .effmach debugger command to switch between "AMD64 view" (i.e. x64) and "ARM64EC view". Launch the debugger and first type in .effmach arm64 and dump the registers using r. Then type .effmach amd64 and r look at the register dump that produces:
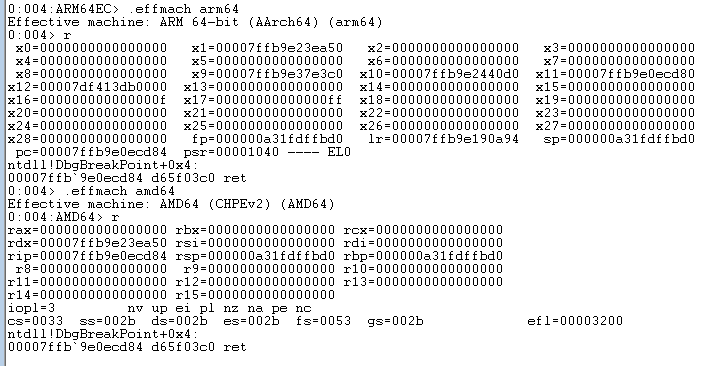
Remember, we are stopped at the same breakpoint at the same RET instruction, and yet the debugger is able represent the ARM64 state as a valid x64 state. Compare the registers and you will see X0 ==RCX, X1 == RDX, PC == RIP, SP == RSP. Even if you didn't have the register mapping table I presented above, and you didn't peek at winnt.h, you could through trial and error derive the register mapping by modifying a given register in one view and then use .effmach to switch views and see which register is modified. You can confirm for yourself that there is in fact a 1:1 register mapping between x64 and ARM64EC.
Notice that in both views, the debugger still displays "ARM64EC" at the prompt and disassembles the correct ARM64 RET instruction at the program counter. First it would not make sense to try to disassemble the bytecode D65F03C0 as Intel code. But second, how does the debugger know this is ARM64 bytecode and not x64 bytecode? (This is the same question I raised earlier about how does "link -dump -disasm" know)
That's where it EC Bitmap comes in, the data structure I mentioned which maintains the architecture state of every single 4K page of the address space of a process. Yes, that's a lot of bits, since 64-bit Windows processes contain 47 bits of address space (or 128 terabytes) which dividing by 4096 bytes-per-page means there are 32 billion pages or 4 gigabytes of bitmap - per process!. That's ok, the bitmap is sparsely allocated by the kernel and allocated only as modules (EXEs and DLLs) are mapped in, so the true memory footprint of the EC bitmap in each process is miniscule.
It is during the loading of binaries into a process that the OS checks the ARM64X metadata, which contains a table of ranges specifying which address ranges of the binary are ARM64EC and which are not. The metadata is how the linker knows and how link -dump -disasm knows the architecture of a given instruction. You can view this metadata in an ARM64X binary by using the linker's -loadconfig command:
link -dump -loadconfig cmd.exe
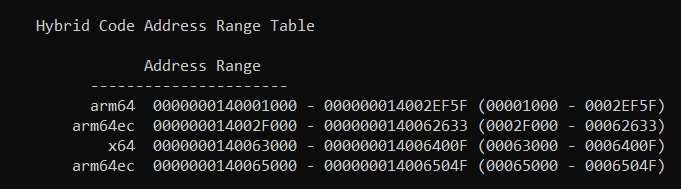
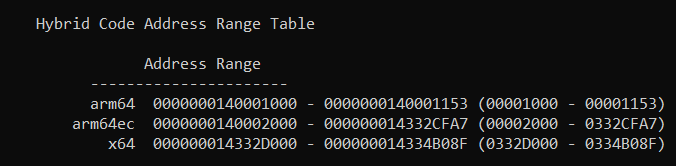
Note that CMD.EXE contains _3_ types of code ranges: classic ARM64, ARM64EC, and x64. The x64 is the smallest section since it contains mainly the Fast Forward Sequences which will only be accessed during emulation. A larger section is pure classic ARM64 which is unique to when CMD.EXE is launched as classic ARM64. But the vast majority of the code is ARM64EC as expected. The ARM64EC sections (two of them, one contains functions, the other contains thunks) are commom, meaning:
- when running as a "classic" ARM64 process, both the ARM64 and ARM64EC code sections will be used and executed natively.
- when running as an emulated x64 process or an ARM64EC process (same thing!), the x64 and ARM64EC sections will be used. The code in the classic ARM64 range will be inaccessible.
The Windows SDK exports a function called RtlIsEcCode() which allows a user mode process to query its own EC bitmap to determine if a target function address is valid a ARM64EC target or a foreign x64 target. The EC bitmap is how the debugger knows the architecture of a code page at run time, and that's how the x64 emulator itself knows when it is emulating an Intel CALL or JMP or RET which architecture it is branching to.
To answer the question "is Microsoft Office on ARM64 native or emulated?" let's do the same thing on say, Outlook.exe and Excel.exe:
link -dump -loadconfig outlook.exe
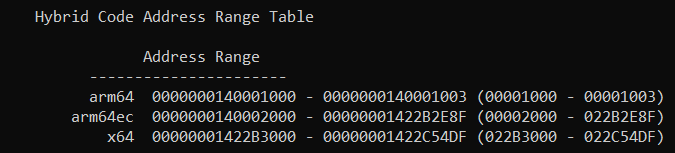
link -dump -loadconfig excel.exe
You can see that the vast majority of the code - over 34 megabytes of Outlook.exe and over 51 megabytes of Excel.exe - are in fact ARM64EC native code ranges. There is on the order of 100 kilobytes of x64 code in each, which a quick disassembly shows to be a lot of entry/exit thunks, but interestingly also what looks to be some hand coded assembly which is likely related to interacting with legacy x64 Office plugins.
So far so good, it would appear that the main application .EXE binaries are almost entirely native ARM64 code. Let's dig further...
I'll cover code translation in more detail in the emulation tutorial. A quick way to tell if an application is generating a lot of x86-to-ARM64 or x64-to-ARM64 translations (which indicates emulation is taking place) is to look in the subdirectory C:\Windows\XtaCache. This is where both xtajit and xtajit64 cache their code translations. You can judge by the size of a .JC (jit cache) file how much emulator code each specific binary is generating. So I go and launch Outlook, Word, Excel, and PowerPoint and use them a bit and exit, I can now check the XtaCache subdirectory and sort by date to see exactly which binaries are touched by the emulator and how much:
C:\Windows> dir /a /Od XtaCache
01/23/2024 05:54 AM 88,680 OUTLOOK.EXE.BB1C9B41ACF02FA754BB74F904EEECF8.28F307BCA34BF44EAC10A7104D0E223C.x64.mp.1.jc
01/23/2024 05:54 AM 168,606 WEBVIEW2LOADER.DLL.F7A965A9458230A54892AF2CE984AA46.00050C948F07C2E25A75BC49121A5924.x64.mp.1.jc
01/23/2024 06:09 AM 71,468 TAIL.EXE.EF21B14F854F1EBED50BA626799C7F79.9BFA6B654B9A942355FC2ED954ABDC5D.x64.mp.1.jc
01/23/2024 06:22 AM 131,234 OART.DLL.601AFE7C3A54F2E89F06B7CF0CC4C696.3CE8CCE3ED05781A877981D0D62BB5BF.x64.mp.1.jc
01/23/2024 06:23 AM 64,982 SFC_OS.DLL.351F330D27A1F357C71B6E108284D2AC.D236FAC5EC48DFACF4D07604F5D89D5F.x64.mp.1.jc
01/23/2024 06:23 AM 65,048 SERVICINGCOMMON.DLL.A4EBC5AC7F9BFC175E09FF86605E2F53.03C17FC63C439D666569F49B0C4B66F4.x64.mp.1.jc
01/23/2024 06:23 AM 65,426 CONTAB32.DLL.78710E60F2BBAAD78F442006830850EF.7C9E924620167D6A093C8F2B0743E55C.x64.mp.1.jc
01/23/2024 06:23 AM 193,772 WWLIB.DLL.3F3C95BF9729B8E9B90DFC1B47CF136F.AB7A77F4F0ADB0704A3A4F3944FCE7F5.x64.mp.2.jc
01/23/2024 06:23 AM 67,952 MSOARIA.DLL.49F64D2FFD552D2AEE0066FBB20AC0AA.0B433D08299C6A4B80472261F938961C.x64.mp.1.jc
01/23/2024 06:23 AM 64,994 POWERPNT.EXE.0FA4B625156C7E22114674F97117F987.445CA6519BAA38F94D96C608ACABDE83.x64.mp.1.jc
01/23/2024 06:23 AM 67,568 IGX.DLL.E55FD01ED682C0CF6A860F3CCF40C1E4.598722777E595BE921B62125D4A45EFC.x64.mp.1.jc
01/23/2024 06:23 AM 74,072 GFX.DLL.4688A841C810BE4AA33EBE0CC4EE9D48.527266E60435F17D2ED348AD598F7C0F.x64.mp.1.jc
01/23/2024 06:23 AM 65,498 OUTLOOKSERVICING.DLL.E6FDC7D94FC2E5DC2ED8E44510929958.B52DE03B38FCB44C156D2A5D271CBB55.x64.mp.1.jc
01/23/2024 06:23 AM 80,202 OLMAPI32.DLL.2459AF91A6F406820638793C24F46439.FF855104181457CA8B68CE7523A432FE.x64.mp.1.jc
01/23/2024 06:23 AM 65,804 WINDOWS.DEVICES.BLUETOOTH.DLL.F3D86AA7C586DFA66FC92CC3EECB5472.20B53A6F8C40E20B7B39964CFD7BEC2A.x64.mp.1.jc
01/23/2024 06:23 AM 157,296 IEAWSDC.DLL.32343461F32FEFA26DDDFF1F55DAD5E7.12E5B9EC4939B165D34C06332FD04F16.x64.mp.1.jc
01/23/2024 06:23 AM 64,798 MSO.FRAMEPROTOCOLWIN32.DLL.1533364B4506B30B0A426EA7E5C0D7AA.5547EB87D6620BA52AD21FE6168D5FC5.x64.mp.1.jc
01/23/2024 06:23 AM 64,940 AI.DLL.17F946C18BF38EFAB445C810E0A8E658.81CE4E787F0D8C3956C9BB8B8BE9A173.x64.mp.1.jc
01/23/2024 06:23 AM 64,948 D3D10WARP.DLL.ED3CAD011000588D0F1B27DAF50378CA.2B79EFF5B5150C5D9F1B98A59A0AAABE.x64.mp.1.jc
01/23/2024 06:23 AM 778,368 C2R64.DLL.4FBA42E853A27A798097E91F9242FF56.07F9EDD226D7954A96572137A070070F.x64.mp.4.jc
01/23/2024 06:23 AM 167,564 MSO40UIWIN32CLIENT.DLL.E4E546F2451CDD2988FDFFE4D8B5F687.7C398CFCDD2F68E26F7D60CBCB13E10F.x64.mp.2.jc
01/23/2024 06:23 AM 132,570 MSVCP140.DLL.7D64A17BAE313AF8A41A9F525D5C147A.491D6ABD6095F2F3EFC2D0D5ED69012B.x64.mp.2.jc
01/23/2024 06:23 AM 64,748 COML2.DLL.992843969650CA2377CBC402C350B364.9D89F87B63B4EC2898AFC3C8949E19AE.x64.mp.1.jc
01/23/2024 06:23 AM 163,008 MSO30WIN32CLIENT.DLL.8026AB5960DA1C94D238D79D552A6FC1.23547E6FFC5402E4271FB5950548C91D.x64.mp.2.jc
01/23/2024 06:23 AM 169,744 MSO20WIN32CLIENT.DLL.52241F82F91457A9740F7D4E6C37FA0B.148AC8FF5A06F17BE0DAD9227B368A09.x64.mp.2.jc
01/23/2024 06:23 AM 65,440 MSO50WIN32CLIENT.DLL.E1E2A4C4771314BFFFADAFF2BF28E6A7.2C5A97CB7AF417BF3592C61A341161C7.x64.mp.1.jc
01/23/2024 06:23 AM 167,360 MSO98WIN32CLIENT.DLL.60710D27D93488345B89FB617875154D.64EB2117462B7AB775BD80631DCF8FB5.x64.mp.2.jc
01/23/2024 06:23 AM 73,824 RICHED20.DLL.E76058D10B247544B77BD6DC2FE82963.6DE16CA9E2C7064821B871D72BFA6DBF.x64.mp.1.jc
01/23/2024 06:23 AM 64,734 MSOHEV.DLL.A7CEAACAC2F7E67007AD26927159E2C1.E1F23C163A3F14CC3D4AD152FDC96AE3.x64.mp.1.jc
01/23/2024 06:23 AM 66,090 WINDOWS.UI.IMMERSIVE.DLL.0A0ACBA56219A13F710D183F9FD359D7.36C9170AEE59318A9028824AF69056BA.x64.mp.1.jc
01/23/2024 06:23 AM 64,680 MSIMG32.DLL.8049E381C74F44B50018150D632B01BC.38C4A4D39935EA16464DAAC785851C75.x64.mp.1.jc
01/23/2024 06:23 AM 395,018 REACT-NATIVE-SDK.DLL.F3043F77194AE0F4C21CE74B7D9464A6.9E567FEA2EFC0D5C4FEF6F0B2FA7FB82.x64.mp.2.jc
01/23/2024 06:23 AM 1,202,206 REACT-NATIVE-WIN32.DLL.D6B56BAB43AFD6336C03A817CBDB0CDC.6FB9042A6F80A92B33FCAB32858EAD30.x64.mp.4.jc
01/23/2024 06:23 AM 234,600 DBGHELP.DLL.54150AE99DD539FA29D651AACC8BD84F.C2C0596729F902FC996F7554F8B0EA35.x64.mp.2.jc
01/23/2024 06:23 AM 12,092,252 V8JSI.DLL.77EF9D00D06826F42D239C173D7616EB.40BBABEA5574359C895135C00FD90774.x64.mp.3.jc
01/23/2024 06:23 AM 65,804 MSPTLS.DLL.CD4A6C848C221A6DA8137B3A64CDBB97.6D7A5B97D3C262509BB94C419198FF3A.x64.mp.1.jc
01/23/2024 06:23 AM 65,720 APPRESOLVER.DLL.87B32F3998415F26C49E025AA88BD6A2.48BBBD5A5247C146A18392947AC2AFC1.x64.mp.1.jc
01/23/2024 06:23 AM 65,034 LINKINFO.DLL.FB6621014A23792FFDCD0913064BE8B3.B25146DF7344407349E964EBF28AAAC3.x64.mp.1.jc
01/23/2024 06:23 AM 65,352 NTSHRUI.DLL.A7A81FAC6039E083FABB705A626E8BC7.44F6EF8031A06207D3BEC4029856E74D.x64.mp.1.jc
01/23/2024 06:23 AM 64,678 SRVCLI.DLL.ECF2D659185A38F2A8D3733469034E76.5C98E5AD07C5553505AFAB58B19493F6.x64.mp.1.jc
01/23/2024 06:23 AM 66,040 DAVHLPR.DLL.16C01681FB54FA1B6DA875892C04DA86.C8F7FF58332D95F94BF3421AFF0EAA78.x64.mp.1.jc
01/23/2024 06:23 AM 1,219,144 PIDGENX.DLL.DA3CAEEDF156B2C82D46AEF97CE8BE27.44F6D28474847DB417F8F6F598DFEB6E.x64.mp.1.jc
01/23/2024 06:24 AM 137,104 OMICAUT.DLL.467B6171F144A7200EDD116CE9B15AFA.7A2FE638A220E7A3361054D629B1A6CC.x64.mp.1.jc
01/23/2024 06:24 AM 67,988 CHART.DLL.491FC0D80B97CE83C481C1E0BDBB511F.0B6935B3D0768B91A40430A95D3D2067.x64.mp.1.jc
01/23/2024 06:24 AM 192,108 EXCEL.EXE.D8F34D98A8555E44F03BB09747513981.F1A0C4312A02C493D9D234D7959E03E3.x64.mp.2.jc
01/23/2024 06:30 AM 64,664 MPR.DLL.43D30D29C847C32A8BAA0238326F22F9.C0B39412D82CAD166EC5C7155491CC38.x64.mp.1.jc
01/23/2024 06:30 AM 64,934 DRPROV.DLL.C4A971894F781B8492150A06533D03C5.BB6DE8A28144321073E8D067731720A0.x64.mp.1.jc
01/23/2024 06:30 AM 64,984 DAVCLNT.DLL.BB6DF1D9CB70F9F020E0F9FEEA55521B.227C73329CE2A2A671136EF7B3D8EDCC.x64.mp.1.jc
01/23/2024 06:30 AM 65,298 NTLANMAN.DLL.458B6CC1D2185C6A8C1C4EB29D333898.1750F958BA966845BF0706126AE93C3A.x64.mp.1.jc
01/23/2024 06:30 AM 185,022 MSO.DLL.F7FC0169653B6BB4EA1CAD28F12A178B.D10D3D991194B3DA43A846284A9B7284.x64.mp.2.jc
01/23/2024 06:30 AM 285,790 PPCORE.DLL.D439B9AFD7A8A76DBB5F880225629F3D.5714731BA7ED35CEA09870B29CF1C6BC.x64.mp.3.jc
01/23/2024 06:30 AM 64,694 WUCEFFECTS.DLL.8857335A8A1977C011360E9BE680C087.B67DD01A9FE27B8FBE0F2BA8B4012AD8.x64.mp.1.jc
01/23/2024 06:30 AM 64,676 DXVA2.DLL.4ECAA6EAC676A95E7CB7CA8D69C44063.5DC28671247C0A07EAD917B0636A6E68.x64.mp.1.jc
01/23/2024 06:31 AM 134,102 URLMON.DLL.DC87D10943754E912602DA54DC0A3A52.CCE2FF813765365C077865A69087FFA4.x64.mp.2.jc
Needless to say, Office uses a lot of DLLs and because each process (outlook.exe, winword.exe, excel.exe, powerpnt.exe) is running as ARM64EC, any DLL that they load also has to run in ARM64EC mode which means the emulator is invoked on every single DLL as well.
For technical reasons the minimum size of a .JC file is about 44 kilobytes, so the fact that most of these cached translations are in the 64K to slightly over 100K range is a good sign.
The one cached translation that clearly pops out as heavily emulated (due to the 12 megabytes of cached translation) is V8JSI.DLL which is related to the V8 Javascript engine. So finding that DLL in the Office installation and dumping the header:
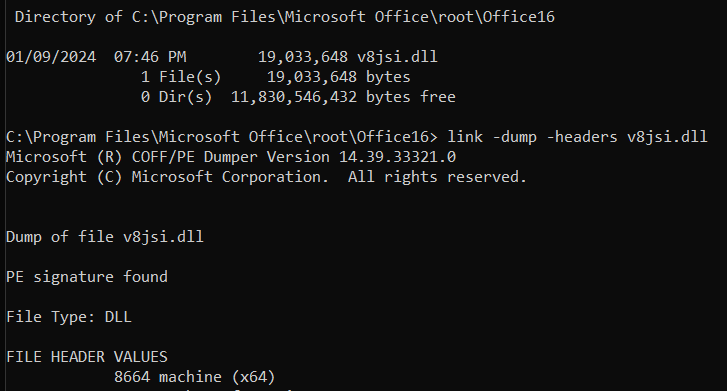
Busted! We clearly see that V8JSI.DLL is not ARM64X but rather is a pure-x64 legacy binary of machine type 8664 and therefore has not been ported to ARM64EC. This means that when executing scripts in Office on ARM64 you will be hitting emulation overhead. "Emulation Compatible" interoperability in action!
Interoperability in action - with some new tricks!
So let's take an even deeper look at an actual ARM64X binary - KERNEL32.DLL.
I choose KERNEL32.DLL because it and NTDLL.DLL are probably the most patched DLLs in the history of Windows. Every debugger, tracing tool, and game anti-cheat mechanism relies on patching certain low-level system calls in KERNEL32 and NTDLL.
Let's make a stupid simple test program which does nothing but return the current tick count returned by the system function GetTickCount(). Below is my sample C source code, the compiled x64 binary code, and the output of the program when I run it from the command line:
#include <windows.h> int main() { return GetTickCount(); } main PROC ; 5 : { 00000 48 83 ec 28 sub rsp, 40 ; 00000028H ; 6 : return GetTickCount(); 00004 ff 15 00 00 00 00 call QWORD PTR __imp_GetTickCount ; 7 : } 0000a 48 83 c4 28 add rsp, 40 ; 00000028H 0000e c3 ret 0 main ENDP D:\GTC_DEMO>gtc & echo %errorlevel% 785812390 D:\GTC_DEMO>gtc & echo %errorlevel% 785812921 D:\GTC_DEMO>gtc & echo %errorlevel% 785815703
Pro tip: every Windows application returns an exit code, just as this test program does. You can query the ERRORLEVEL environment variable to see this return value by using the echo command as shown above.
Notice how the return value above is a nice monotonically increasing value as expected from a millisecond tick counter. If we attach a debugger and single-step the execution of the main() function as it calls into GetTickCount(), it is a straightforward sequence of execution for a grand total of 10 instructions:
0:000> bp main 0:000> g Breakpoint 0 hit gtc!main: 00007ff6`9fea7330 4883ec28 sub rsp,28h 0:000> t gtc!main+0x4: 00007ff6`9fea7334 ff15c69c0900 call qword ptr [gtc!_imp_GetTickCount (00007ff6`9ff41000)] ds:00007ff6`9ff41000={KERNEL32!GetTickCount (00007ffb`0769f540)} 0:000> t KERNEL32!GetTickCount: 00007ffb`0769f540 b92003fe7f mov ecx,offset SharedUserData+0x320 (00000000`7ffe0320) 0:000> t KERNEL32!GetTickCount+0x5: 00007ffb`0769f545 488b09 mov rcx,qword ptr [rcx] ds:00000000`7ffe0320=000000000179d8ff 0:000> t KERNEL32!GetTickCount+0x8: 00007ffb`0769f548 8b04250400fe7f mov eax,dword ptr [SharedUserData+0x4 (00000000`7ffe0004)] ds:00000000`7ffe0004=0fa00000 0:000> t KERNEL32!GetTickCount+0xf: 00007ffb`0769f54f 480fafc1 imul rax,rcx 0:000> t KERNEL32!GetTickCount+0x13: 00007ffb`0769f553 48c1e818 shr rax,18h 0:000> t KERNEL32!GetTickCount+0x17: 00007ffb`0769f557 c3 ret 0:000> t gtc!main+0xa: 00007ff6`9fea733a 4883c428 add rsp,28h 0:000> t gtc!main+0xe: 00007ff6`9fea733e c3 ret
main() returns back to the C runtime which ultimately returns the error code as it terminates the process.
Now the trace above was done on an actual AMD processor, so no ARM64 or emulation is involved. Let's run this exact same binary on an ARM64 device and single-step it in the debugger. Notice that as expected the xtajit64.dll emulator is loaded immediately after NTDLL.DLL:
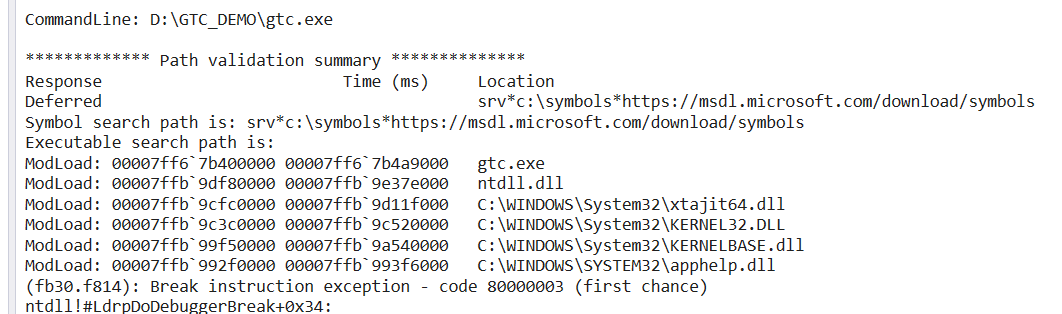
Now single-step, and notice the "EXP+#" name decoration added to the GetTickCount() function in KERNEL32.DLL, this actually the name decoration used on fast forward sequences:
0:000:ARM64EC> bp main
0:000:ARM64EC> g
Breakpoint 0 hit
gtc!main:
00007ff6`7b407270 4883ec28 sub rsp,28h
0:000> t
gtc!main+0x4:
00007ff6`7b407274 ff15869d0900 call qword ptr [gtc!_imp_GetTickCount (00007ff6`7b4a1000)] ds:00007ff6`7b4a1000={KERNEL32!EXP+#GetTickCount (00007ffb`9c4b1070)}
0:000> t
KERNEL32!EXP+#GetTickCount:
00007ffb`9c4b1070 b92003fe7f mov ecx,offset SharedUserData+0x320 (00000000`7ffe0320)
0:000> t
KERNEL32!EXP+#GetTickCount+0x5:
00007ffb`9c4b1075 488b09 mov rcx,qword ptr [rcx] ds:00000000`7ffe0320=000000000302228a
0:000> t
KERNEL32!EXP+#GetTickCount+0x8:
00007ffb`9c4b1078 8b04250400fe7f mov eax,dword ptr [SharedUserData+0x4 (00000000`7ffe0004)] ds:00000000`7ffe0004=0fa00000
0:000> t
KERNEL32!EXP+#GetTickCount+0xf:
00007ffb`9c4b107f 480fafc1 imul rax,rcx
0:000> t
KERNEL32!EXP+#GetTickCount+0x13:
00007ffb`9c4b1083 48c1e818 shr rax,18h
0:000> t
KERNEL32!EXP+#GetTickCount+0x17:
00007ffb`9c4b1087 c3 ret
0:000> t
gtc!main+0xa:
00007ff6`7b40727a 4883c428 add rsp,28h
0:000> t
gtc!main+0xe:
00007ff6`7b40727e c3 ret
Aha, surprise! I tricked you! I am showing a very cool performance optimization in the latest (post-SV2) Windows Insider builds. Remember I said that a fast forward sequence is the x64 entry point for a native ARM64EC function and that normally a FFS is a 16-byte block of code generated by the linker. That is the default behaviour. A developer is able to override this and provide any x64 code sequence as a FFS for a given function.
So what Microsoft has done in the case of GetTickCount() is (after obviously analyzing performance data) is they chosen to replace the default fast-forward sequence which would have invoked native code to instead remain in emulation and emulate the entirety of GetTickCount(). And you can see this FFS implementation of GetTickCount() is identical to the true x64 implementation of GetTickCount() as witnessed on the AMD machine earlier.
Why do this? The cost of transitioning out of emulation to native ARM64EC code and then back into emulation is about 100 to 200 clock cycles, whereas leaving a small function like GetTickCount() emulated only costs a dozen clock cycles or so. Pro tip: Since Windows 11 SV2, Microsoft has gone and accelerated several common Win32 function calls with these custom fast-forward sequences. You can see these by disassembling other parts of that same code page:
KERNEL32!EXP+#GetCurrentProcessId: 00007ffb`9c4b1000 65488b042540000000 mov rax,qword ptr gs:[40h] 00007ffb`9c4b1009 c3 retKERNEL32!EXP+#GetCurrentProcess: 00007ffb`9c4b1010 4883c8ff or rax,0FFFFFFFFFFFFFFFFh 00007ffb`9c4b1014 c3 retKERNEL32!EXP+#GetCurrentThreadId: 00007ffb`9c4b1020 65488b042548000000 mov rax,qword ptr gs:[48h] 00007ffb`9c4b1029 c3 ret KERNEL32!EXP+#GetCurrentThread: 00007ffb`9c4b1030 48c7c0feffffff mov rax,0FFFFFFFFFFFFFFFEh 00007ffb`9c4b1037 c3 ret
Common functions such as GetCurrentProcessId(), GetCurrentProcess(), GetCurrentThreadId(), and GetCurrentThread() are all accelerated. The vast majority of Win32 calls are not accelerated of course and will have the default 16-byte FFS. You can poke around and view these for a given module by listing all the "EXP+" symbols and then looking at how they are implemented. For example this a few lines of output (of hundreds) for KERNEL32.DLL:
0:000:ARM64EC> X kernel32!EXP*
00007ffb`9c3c1ef0 KERNEL32!EXP+#EnableThreadProfiling (EXP+#EnableThreadProfiling)
00007ffb`9c3c3c50 KERNEL32!EXP+#LZDone (EXP+#LZDone)
00007ffb`9c3c3470 KERNEL32!EXP+#GetUserDefaultLCID (EXP+#GetUserDefaultLCID)
00007ffb`9c3c5420 KERNEL32!EXP+#VDMConsoleOperation (EXP+#VDMConsoleOperation)
00007ffb`9c3c42a0 KERNEL32!EXP+#QueryActCtxW (EXP+#QueryActCtxW)
00007ffb`9c3c1200 KERNEL32!EXP+#BaseCleanupAppcompatCacheSupportWorker (EXP+#BaseCleanupAppcompatCacheSupportWorker)
00007ffb`9c3c15a0 KERNEL32!EXP+#BasepReleasePackagedAppInfo (EXP+#BasepReleasePackagedAppInfo)
00007ffb`9c3c5960 KERNEL32!EXP+#lstrcat (EXP+#lstrcat)
00007ffb`9c3c39b0 KERNEL32!EXP+#IsValidCalDateTime (EXP+#IsValidCalDateTime)
00007ffb`9c3c4350 KERNEL32!EXP+#QueryPerformanceFrequency (EXP+#QueryPerformanceFrequency)
The next thing to know: if you drop the "EXP+" portion of the name decoration, the resulting function name, e.g. #GetTickCount, is the true ARM64EC entry point of the function.
So let's take a look at another function exported by KERNEL32.DLL which is currently not accelerated in build 26020 at the time of this writing, QueryPerformanceFrequency(). If we disassemble its fast-forward sequence we see the default 16-byte pattern:
KERNEL32!EXP+#QueryPerformanceFrequency:
00007ffb`9c3c4350 488bc4 mov rax,rsp
00007ffb`9c3c4353 48895820 mov qword ptr [rax+20h],rbx
00007ffb`9c3c4357 55 push rbp
00007ffb`9c3c4358 5d pop rbp
00007ffb`9c3c4359 e902af0600 jmp KERNEL32!#QueryPerformanceFrequencyStub (00007ffb`9c42f260)
00007ffb`9c3c435e cc int 3
00007ffb`9c3c435f cc int 3
Given that QPF returns a fixed value during the whole time an application is running, one could argue this function should be accelerated ;-) But I digress.
If we follow that target address of the JMP (and notice the target symbol is decorated only with the # so we know the target is going to be ARM64EC code and thus ARM64 bytecode, and voila...):
KERNEL32!#QueryPerformanceFrequencyStub:
00007ffb`9c42f260 17fff5a4 b KERNEL32!#QueryPerformanceFrequency (00007ffb`9c42c8f0)
ok so now let's follow that jump which clearly targets another ARM64EC function:
KERNEL32!#QueryPerformanceFrequency:
00007ffb`9c42c8f0 f00006f0 adrp xip0,KERNEL32!_imp_aux_SetThreadPreferredUILanguages (00007ffb`9c50b000)
00007ffb`9c42c8f4 f9430a10 ldr xip0,[xip0,#0x610]
00007ffb`9c42c8f8 d61f0200 br xip0
and we see that KERNEL32's QueryPerformanceFrequency() is just a DLL import stub, so we follow that indirect jump (the import address is loaded by the ADRP + LDR instructions above, so I use the debugger's dq command to dump the memory being loaded and then disassemble that address):
0:000:ARM64EC> dq 00007ffb`9c50b000 + 610
00007ffb`9c50b610 00007ffb`9e11a220 00000000`00000000
This address ultimately leads to NTDLL!'s RtlQueryPerformanceFrequency() which truly implements the function and returns the value:
0:000:ARM64EC> u 00007ffb`9e11a220
ntdll!#RtlQueryPerformanceFrequency:
00007ffb`9e11a220 d2806008 mov x8,#0x300
00007ffb`9e11a224 f2afffc8 movk x8,#0x7FFE,lsl #0x10
00007ffb`9e11a228 f9400108 ldr x8,[x8]
00007ffb`9e11a22c f9000008 str x8,[x0]
00007ffb`9e11a230 52800020 mov w0,#1
00007ffb`9e11a234 d65f03c0 ret
So to summarize: x64 FFS jumps to ARM64EC stub which jumps to ARM64EC import thunk which jumps to ARM64EC target function. Whew!
Let's compile a QueryPerformanceFrequency() test case as x64 and verify this is what happens:
#include <windows.h> int main() { __int64 f; QueryPerformanceFrequency(&f); return (int)f; }
D:\GTC_DEMO>qpf & echo %ERRORLEVEL% 10000000 D:\GTC_DEMO>qpf & echo %ERRORLEVEL% 10000000 D:\GTC_DEMO>qpf & echo %ERRORLEVEL% 10000000
That looks good, 10 MHz is the usual value returned by Windows 11. Ok, now let's debug it on an ARM64 device!
We know that main() is x64 code, so we need to type .effmach amd64 just to make sure the debugger disassembles correctly. We see that the compiled calls to QueryPerformanceFrequency() resolves to an indirect call through an import table entry to KERNEL32.DLL and points at an obvious FFS:
0:000:ARM64EC> .effmach amd64 Effective machine: x64 (AMD64) 0:000> u main qpf!main [D:\GTC_DEMO\qpf.c @ 5]: 00007ff6`5ec07270 4883ec38 sub rsp,38h 00007ff6`5ec07274 488d4c2420 lea rcx,[rsp+20h] 00007ff6`5ec07279 ff15819d0900 call qword ptr [qpf!_imp_QueryPerformanceFrequency (00007ff6`5eca1000)] 00007ff6`5ec0727f 8b442420 mov eax,dword ptr [rsp+20h] 00007ff6`5ec07283 4883c438 add rsp,38h 00007ff6`5ec07287 c3 ret 0:000> dq 00007ff6`5eca1000 00007ff6`5eca1000 00007ffb`9c3c4350 00007ffb`9c3c4340 0:000> u 00007ffb`9c3c4350 KERNEL32!EXP+#QueryPerformanceFrequency: 00007ffb`9c3c4350 488bc4 mov rax,rsp 00007ffb`9c3c4353 48895820 mov qword ptr [rax+20h],rbx 00007ffb`9c3c4357 55 push rbp 00007ffb`9c3c4358 5d pop rbp 00007ffb`9c3c4359 e902af0600 jmp KERNEL32!#QueryPerformanceFrequencyStub (00007ffb`9c42f260)
At this point we know the target of the FFS is going to be ARM64 bytecode, so we switch views back to ARM64EC and follow that target. That target itself has an indirect jump through another import table entry which eventually leads us to the real function in NTDLL.DLL:
0:000> .effmach arm64ec
Effective machine: ARM64EC (CHPEv2 on X64) (ARM64EC)
0:000:ARM64EC> u 00007ffb`9c42f260
KERNEL32!#QueryPerformanceFrequencyStub:
00007ffb`9c42f260 17fff5a4 b KERNEL32!#QueryPerformanceFrequency (00007ffb`9c42c8f0)
0:000:ARM64EC> u 00007ffb`9c42c8f0
KERNEL32!#QueryPerformanceFrequency:
00007ffb`9c42c8f0 f00006f0 adrp xip0,KERNEL32!_imp_aux_SetThreadPreferredUILanguages (00007ffb`9c50b000)
00007ffb`9c42c8f4 f9430a10 ldr xip0,[xip0,#0x610]
00007ffb`9c42c8f8 d61f0200 br xip0
0:000:ARM64EC> dq 00007ffb`9c50b000 + 610
00007ffb`9c50b610 00007ffb`9e11a220 00000000`00000000
0:000:ARM64EC> u 00007ffb`9e11a220
ntdll!#RtlQueryPerformanceFrequency:
00007ffb`9e11a220 d2806008 mov x8,#0x300
00007ffb`9e11a224 f2afffc8 movk x8,#0x7FFE,lsl #0x10
00007ffb`9e11a228 f9400108 ldr x8,[x8]
00007ffb`9e11a22c f9000008 str x8,[x0]
00007ffb`9e11a230 52800020 mov w0,#1
00007ffb`9e11a234 d65f03c0 ret
Note the # name decoration, which indicates (as expected) that NTDLL is an ARM64X binary and the RtlQueryPerformanceFrequency function is actually ARM64EC.
But I've skipped a step between when we were in the FFS and then magically appeared in ARM64EC code - the argument and return value marshalling. The caller main() passes a pointer in RCX which needs to be marshaled to the callee's X0, and the callee RtlQueryPerformanceFrequency() returns a boolean in W0 which needs to be marshaled back to the caller's EAX. Where is the code which marshals those arguments?
As I explained with xtabase, the emulator could blindly assume a mapping RCX->X0, RDX->X1, etc. and this would work fine most of the time (since that is the ARM64EC_NT_CONTEXT mapping), but not always. When the call involves more than 4 arguments, or data structures being passed by value, arguments might need to be swizzled around. And we definitely know the return value does need marshalling since the ARM64EC will return the value in W0 or X0 (which corresponds to the x64 ECX or RCX registers) but it needs to end up in EAX/RAX (W8/X8). I did not show any such code above.
This is where a special detail of ARM64EC comes in - all ARM64EC functions (compiled C/C++ as well as ASM and FFS) need to be 16-byte aligned. This is pretty good advice anyway since most x64 compilers and ARM64 compilers already 16-byte-align their functions. Functions don't generally end on a perfect 16-byte boundary so compilers insert padding bytes such as zeroes or NOP instructions to bump the code up to the next 16-byte boundary. ARM64EC takes advantage of this padding by placing a special 32-bit value into the 4 bytes preceding the start of an ARM64EC function.
Let's disassemble ntdll!#RtlQueryPerformanceFrequency as we just did above, but this time starting 4 bytes earlier:
0:000:ARM64EC> u 00007ffb`9e11a220 - 4
00007ffb`9e11a21c 001296d9 ???
ntdll!#RtlQueryPerformanceFrequency:
00007ffb`9e11a220 d2806008 mov x8,#0x300
00007ffb`9e11a224 f2afffc8 movk x8,#0x7FFE,lsl #0x10
00007ffb`9e11a228 f9400108 ldr x8,[x8]
00007ffb`9e11a22c f9000008 str x8,[x0]
00007ffb`9e11a230 52800020 mov w0,#1
00007ffb`9e11a234 d65f03c0 ret
That special non-zero (and clearly bogus ARM64 instruction) is actually a signed 32-bit offset. For technical reasons the low bit is always set, so really the value we care about in this case is 0x001296D8. What happens if we apply that offset value to the address of the function:
0:000:ARM64EC> u 00007ffb`9e11a220 + 001296d8
ntdll!$ientry_thunk$cdecl$i8$i8:
00007ffb`9e2438f8 d503237f pacibsp
00007ffb`9e2438fc adbb1fe6 stp q6,q7,[sp,#-0xA0]!
00007ffb`9e243900 ad0127e8 stp q8,q9,[sp,#0x20]
00007ffb`9e243904 ad022fea stp q10,q11,[sp,#0x40]
00007ffb`9e243908 ad0337ec stp q12,q13,[sp,#0x60]
00007ffb`9e24390c ad043fee stp q14,q15,[sp,#0x80]
00007ffb`9e243910 a9bf7bfd stp fp,lr,[sp,#-0x10]!
00007ffb`9e243914 910003fd mov fp,sp
00007ffb`9e243918 d63f0120 blr x9
00007ffb`9e24391c aa0003e8 mov x8,x0
00007ffb`9e243920 a8c17bfd ldp fp,lr,[sp],#0x10
00007ffb`9e243924 ad443fee ldp q14,q15,[sp,#0x80]
00007ffb`9e243928 ad4337ec ldp q12,q13,[sp,#0x60]
00007ffb`9e24392c ad422fea ldp q10,q11,[sp,#0x40]
00007ffb`9e243930 ad4127e8 ldp q8,q9,[sp,#0x20]
00007ffb`9e243934 acc51fe6 ldp q6,q7,[sp],#0xA0
00007ffb`9e243938 d50323ff autibsp
00007ffb`9e24393c d00005d0 adrp xip0,ntdll!LdrpGuardArm64xDispatchIcallNoESFptr+0x5628 (00007ffb`9e2fd000)
00007ffb`9e243940 f9462a10 ldr xip0,[xip0,#0xC50]
00007ffb`9e243944 d61f0200 br xip0
Aha, an entry thunk! The C/C++ compiler emits entry and exit thunks since it best knows the function signatures of the functions it is compiling. The linker then magically injects the 32-bit signed offset to the entry thunk to the 4 bytes prior to the start of the ARM64EC function. The x64 emulator knows to look there as it dispatches the JMP instruction in the FFS, and in reality transitions to the entry thunk, passing the address of the target ARM64EC function in the X9 register. That is hidden step I skipped earlier: the emulator does not jump directly from the FFS to the start of the ARM64EC function, but rather to its entry thunk.
You can see above the entry thunk clearly creates a stack frame (the STP FP,LR instruction), calls the ARM64EC function via the "BL X9" instruction, and then upon return it correctly moves the return value from RCX/X0 to RAX,X8, tears down the stack frame, and then tail-jumps through a pointer which leads it back into the x64 emulator.
To save code space, entry thunks are not unique for each ARM64EC function; rather, they are unique per call signature. In this case, the name of the entry thunk says it all:
ntdll!$ientry_thunk$cdecl$i8$i8:
The first $i8 indicates that the return value is an 8-byte integer (i.e. int64). The second $i8 indicates that the first function argument is also an 8-byte integer, really a 64-bit pointer in this case.
Why all the spilling of Q6-Q15 vector registers? This has to do with subtle differences between Windows x64 ABI and Windows ARM64 ABI. The Intel x64 calling convention considers registers XMM6-XMM15 to be non-volatile, i.e. callee-save. These registers must not be destroyed by the called function. On the other hand, the ARM64 calling convention considers portions of all 32 NEON vector registers as scratch. This difference was not reconciled for ARM64EC code generation, so unfortunately the C/C++ compiler has to be conservative and preserve those registers in the entry thunk - even though in this case QueryPerformanceFrequency() clearly does not touch any vector registers.
The easy workaround would have been for Microsoft to slightly harden the ARM64EC ABI (and possibly even the native ARM64 ABI) to always preserve the full registers Q8-Q15 in the callee by marking them as non-volatile while only preserving Q6 and Q7. This unfortunate omission means that all x64-to-ARM64EC round trips take this additional penalty of 5 extra STP instructions and 5 extra LDP instructions on every round trip and add slight code bloat to all ARM64X binaries. Remember I mentioned it takes 100 to 200 clock cycles for such a transition, well you're exactly looking at one of the reasons why.
When incrementally porting your application from Intel to ARM, be aware that transitioning between modes has cost, and it will create additional stack frames which would not normally be there on a pure x64 hardware or on classic ARM64. Notice if I set a breakpoint in ntdll!#RtlQueryPerformanceFrequency and then dump the call stack using the k command:
Breakpoint 1 hit ntdll!#RtlQueryPerformanceFrequency: 0:000:ARM64EC> k # Arch Child-SP RetAddr Call Site 00 ARM64EC 00000062`e6d6fc10 00007ffb`9c4adf14 ntdll!#RtlQueryPerformanceFrequency 01 ARM64EC 00000062`e6d6fc10 00007ff6`5ec0727f KERNEL32!$ientry_thunk$cdecl$i8$i8+0x24 02 AMD64 00000062`e6d6fcc0 00007ff6`5ec074cc qpf!main+0xf [qpf.c @ 9] 03 AMD64 (Inline Function) --------`-------- qpf!invoke_main+0x22 [D:\a\_work\1\s\src\vctools\crt\vcstartup\src\startup\exe_common.inl @ 78] 04 AMD64 00000062`e6d6fd00 00007ffb`9c4ae76c qpf!__scrt_common_main_seh+0x10c [D:\a\_work\1\s\src\vctools\crt\vcstartup\src\startup\exe_common.inl @ 288] 05 ARM64EC 00000062`e6d6fd40 00007ffb`9c42f568 KERNEL32!$iexit_thunk$cdecl$i8$i8+0x1c 06 ARM64EC 00000062`e6d6fd70 00007ffb`9e16d1e4 KERNEL32!#BaseThreadInitThunk+0x48 07 ARM64EC 00000062`e6d6fd80 00000000`00000000 ntdll!#RtlUserThreadStart+0x54
The entry thunk stack frame is visible on the call stack. Similarly when the thread initialization code in KERNEL32.DLL (which is ARM64EC) calls in to the test binary and transitions to emulated x64, the exit thunk frame is also visible on the call stack. Keep this in mind if you are writing any kind of tool which performs stack walking. Regardless, this is a small price to pay for seamless argument marshalling.
Pro tip: on the topic of small functions, the Visual C/C++ compiler does not always honor the "inline" keyword which may cause C++ member functions marked as inline to actually be emitted either as x64 or ARM64EC code. Use the __forceinline keyword on small functions to help avoid the x64->ARM64EC->x64 mode transitions and the additional thunk frames when porting such small functions.
Now I compile the same QueryPerformanceFrequency test case as plain "classic" ARM64, no -arm64EC switch specified. If we load that binary into the debugger we can easily see the flow of control from main() to the implemented of RtlQueryPerformanceFrequency. Note that no fast-forward sequences, thunks, or emulation is involved, as expected. All execution remains as native ARM64 codebytes:
0:000:ARM64EC> u main qpf!main [qpf.c @ 5]: 00007ff6`40df4838 a9be7bfd stp fp,lr,[sp,#-0x20]! 00007ff6`40df483c 910003fd mov fp,sp 00007ff6`40df4840 910043e0 add x0,sp,#0x10 00007ff6`40df4844 94000548 bl qpf!QueryPerformanceFrequency (00007ff6`40df5d64) 00007ff6`40df4848 f9400be8 ldr x8,[sp,#0x10] 00007ff6`40df484c 2a0803e0 mov w0,w8 00007ff6`40df4850 2a0003e0 mov w0,w0 00007ff6`40df4854 a8c27bfd ldp fp,lr,[sp],#0x20 00007ff6`40df4858 d65f03c0 ret0:000:ARM64EC> u 00007ff6`40df5d64 qpf!QueryPerformanceFrequency: 00007ff6`40df5d64 90000530 adrp xip0,qpf!_hybrid_auxiliary_iat (00007ff6`40e99000) 00007ff6`40df5d68 f940b210 ldr xip0,[xip0,#0x160] 00007ff6`40df5d6c d61f0200 br xip0 0:000:ARM64EC> dq 00007ff6`40e99000 + 160 00007ff6`40e99160 00007ffb`9c42f260 00007ffb`9c42f290 0:000:ARM64EC> u 00007ffb`9c42f260 KERNEL32!#QueryPerformanceFrequencyStub: 00007ffb`9c42f260 17fff5a4 b KERNEL32!#QueryPerformanceFrequency (00007ffb`9c42c8f0) 0:000:ARM64EC> u 00007ffb`9c42c8f0 KERNEL32!#QueryPerformanceFrequency: 00007ffb`9c42c8f0 f00006f0 adrp xip0,KERNEL32!_imp_aux_SetThreadPreferredUILanguages (00007ffb`9c50b000) 00007ffb`9c42c8f4 f9430a10 ldr xip0,[xip0,#0x610] 00007ffb`9c42c8f8 d61f0200 br xip0 0:000:ARM64EC> dq 00007ffb`9c50b000 + 610 00007ffb`9c50b610 00007ffb`9e11a220 00000000`00000000 0:000:ARM64EC> u 00007ffb`9e11a220 ntdll!#RtlQueryPerformanceFrequency: 00007ffb`9e11a220 d2806008 mov x8,#0x300 00007ffb`9e11a224 f2afffc8 movk x8,#0x7FFE,lsl #0x10 00007ffb`9e11a228 f9400108 ldr x8,[x8] 00007ffb`9e11a22c f9000008 str x8,[x0] 00007ffb`9e11a230 52800020 mov w0,#1 00007ffb`9e11a234 d65f03c0 ret
Note the same # name decoration - because ARM64EC compiled bytecode _is_ valid ARM64 code, the ARM64EC and the ARM64 versions of RtlQueryPerformanceFrequency are in fact one and the same function in memory and in the binary. We can see that both my x64 test binary and the classic ARM64 test binary both end up at the same code address - 7FFB9E11A220 the common address of the ARM64EC RtlQueryPerformanceFrequency() function.
Therefore, whether the caller was emulated x64 or classic ARM64, we arrived at the exact same called function which is both ARM64EC _and_ ARM64. This is called "folding" and is performance by the linker so that there are no duplicate (yet identical) ARM64EC and ARM64 versions of the same function in the binary.
This is the clearest example of the difference between fat binary vs. hybrid binary:
- In a fat binary there would have been both x64 and classic ARM64 versions of every single function spread across two slices, roughly doubling the size of the binary over a pure classic ARM64 binary.
- In a hybrid binary there is generally only one copy a function (as ARM64 bytecode) which can be called from either emulated x64, native ARM64EC, or native classic ARM64 callers. In practice an ARM64X hybrid binary will have about 30% code bloat over a pure classic ARM64 binary (due to thunks and FFS overhead).
- As I demonstrated with the GetTickCount() example, it is possible to replace an ARM64EC's FFS with the full body of that function. Taking this to the extreme and emitting a FFS for every ARM64EC function with the x64 compilation of that same function, you would end up with what is essentially a fat binary. Fat binaries are just a special extreme case of hybrid binaries.
The hybrid binary approach of having only one full version of a function in a binary ultimately saved hundreds of megabytes of disk space in Windows 11 compared to a fat binary or multiple binary approach.
The drawbacks of and technical debt in ARM64EC
It would not be fair for me to end this tutorial without highlight some pitfalls and known problems with the ARM64EC design. I've already pointed out the overhead of switching between x64 and ARM64EC modes and the additional stack frames caused by thunks. That is by design. In fact Apple's original 68020 emulator for PowerPC had a similar concept to the additional stack frames from switch modes. If I remember correctly they were called "switch frames". Now lets look at some undesirable behavior.
One big gotcha to look for - because the entry thunks are generated at compile time of the caller function, make sure that caller and callee's function signatures match! Particularly if one side uses varargs and the other side declares a very specific function signature, ARM64EC argument marshalling will break. This is true in any kind of cross-process function call marshalling but with ARM64EC can occur even in the same process in the same binary. This is not a bug of the ARM64EC design per se, but rather a result of buggy source code.
I hit this gotcha myself when porting the Xformer 10 Atari 8-bit emulator to ARM64EC a couple of years ago. For years the Xformer code base compiled and ran just fine as 32-bit x86, 64-bit x64, and even 64-bit ARM64, but the whole time was masking a real bug in my source code. In my header files I was lazily declaring some functions signatures using "..." syntax which makes them varags. But the functions themselves were not implemented using varargs - I was just lazy defining my function signatures. This worked by accident for 30 years, but once compiled ARM64EC it crashed every time a specific function was called.
If you look my Github repository for Xformer 10 and look at the git log and specifically this commit which finally fixed the problem: 77af224d59d2b8182e0ea6d81d6d91b89910e77a you will see what I mean. I had two different sets of functions with different function signatures which I was calling using the same varargs declaration. Fortunately it took me under an hour to track down and fix this issue and get the ARM64EC build working and tested, technically more than the "matter of minutes" that I promised.
To add to my stupidity the compiler was warning me, but I was ignoring the compiler warning. Pro tip: don't ignore compiler warnings. :-)
A design limitation of x64 emulation, ARM64EC, and softintrinsics today is that only Intel SSE instructions and Intel intrinsics are supported (up to and including SSE4.2 with AES). This is due to us choosing not to map the high 16 NEON registers into the ARM64EC context (where they could serve as the upper halves of the YMM0-YMM15 registers), motivated by an upper management decision that SSE4.2 support was "good enough". SSE4.2 is sufficient to satisfy Windows 11 minimum hardware requirements on AMD and Intel hardware. The Microsoft Surface Go tablet for example is a Windows 11-compatible device which only supports SSE4.2 (due to its use of the Intel Pentium Gold processor). I actually use the Surface Go as a reference device since it very close matches in hardware what the emulator implements in software.
What this means is that in ARM64EC, soft intrinsics, and in x64 emulation there is no AVX or AVX2 support or any kind of 256-bit register state support. This is not a problem in the vast majority of Windows apps _yet_, since most either don't use AVX, don't use Intel intrinsics at all, or can #ifdef out such code to build a pure SSE version of the binary to stay compatible with older Windows 7 machines. But Windows developers don't sit still, they target new hardware features.
One only need track the Steam Hardware Survey to see that in the past two years alone the prevalence of AVX and AVX2 capability in Steam users' hardware has jumped to 96% for AVX and 92% for AVX2. (as expected the prevalence of SSE3 and SSE4.x is in the 99% to 100% range, of course it is). Two years ago the AVX still in the 80's percentage, so that it is now at 96% today worries me a lot.
When I was still at Microsoft in 2022 I was arguing the case that it was time to implement AVX and AVX2 across the board, but I failed to convince management or my peers of the urgency of this proposal. The big risk to Windows on ARM is that as more games and benchmarks (such as Cinebench 2024) drop SSE support entirely and require AVX2, the usefulness of Microsoft's emulator (and thus ARM64EC) may diminish in the near future. And without adequate Intel compatibility the Windows on ARM platform may die. To believe that thousands of independent Windows developers will all magically port their apps to native ARM64 is foolish, and Windows RT and Windows Phone are prime example of Microsoft failing to rally enough developers onto a new platform. Not to mention the whole point of why I am writing these tutorials is because I can plainly see that most Windows developers know nothing about ARM64 or ARM64EC. So providing rock solid reliable emulation is crucial, and must keep evolving hand-in-hand with ARM64EC to support AVX and AVX2 as soon as possible.
I'll discuss emulation in more detail in a separate tutorial and the concept of developing a third-party x64 emulator to replace xtajit64.
There are some known Visual C/C++ compiler bugs that I find surprising. The first is that AVX/AVX2 calling convention and data types are not supported by the ARM64EC compiler. For example if I try to compile this trivial line of code with the -arm64EC switch:
D:\> type i256.c
#include <windows.h>
#include <intrin.h>
__m256i __vectorcall same(__m256i vector) { return vector; }
D:\> cl -Gv -O2 -c -FAsc -arm64EC i256.c
cl : Command line warning D9002 : ignoring unknown option '-Gv'
i256.c
D:\i256.c : error C7302: AVX types (__m256) are not currently supported in ARM64EC code
D:\i256.c : error C7301: __vectorcall calling convention is not currently supported
D:\i256.c : error C7302: AVX types (__m256) are not currently supported in ARM64EC code
Not only does the compiler not understand the -Gv command line switch (which x86 and x64 do) but it refuses to compile the code. Even if you ignore the -Gv warning and try to define a custon __m256 data type, the compiled code would not be able to interoperate since the default entry and exit thunks would be bogus and marshalling would break.
If I change the source to only use __m128i but keep the __vectorcall keyword, it crashes the compiler!
D:\> type i128.c
#include <windows.h>
#include <intrin.h>
__m128i __vectorcall same(__m128i vector)
{
return vector;
}
D:\> cl -Gv -O2 -c -FAsc -arm64EC i128.c
Microsoft (R) C/C++ Optimizing Compiler Version 19.39.33321 for ARM64
Copyright (C) Microsoft Corporation. All rights reserved.
cl : Command line warning D9002 : ignoring unknown option '-Gv'
i128.c
D:\i128.c : error C7301: __vectorcall calling convention is not currently supported
D:\i128.c : fatal error C1001: Internal compiler error.
(compiler file 'D:\a\_work\1\s\src\vctools\Compiler\Utc\src\p2\main.c', line 235)
To work around this problem, try simplifying or changing the program near the locations listed above.
If possible please provide a repro here: https://developercommunity.visualstudio.com
Please choose the Technical Support command on the Visual C++
Help menu, or open the Technical Support help file for more information
These three bugs have been a known blockers for ARM64EC for years. I even formally filed the __vectorcall bug a year ago after I'd left Microsoft so I could track the issue, and it is still unfixed:
https://developercommunity.visualstudio.com/t/VC-176-preview-1-x86-compiler-bad-cod/10291481
The __vectorcall keyword turns out to be problematic even with the Intel 32-bit x86 compiler (which in theory supported this keyword since 2013) as per this bug I filed a year ago which remains unfixed but looks like it may be getting a fix soon:
https://developercommunity.visualstudio.com/t/VC-176-preview-1-x86-compiler-bad-cod/10291483
Microsoft should be much more concerned that ARM64EC is not quite complete. Even though it exited "experimental" mode starting with VS2022 17.4, until there is parity with AVX2 the product is not complete. Agree?
Thank you for sticking through a rather technical tutorial. And if you missed the link at the beginning, do watch Pedro's incremental porting tutorial and please let me know (or him) if you do try porting an app and run into problems like the ones I described.
[ARM64 Boot Camp: Table Of Contents] [Return to Emulators.com]